
 Technologie-Peripherieger?te
KI
Erstellen Sie Ihre erste LLM -Anwendung: Ein Anf?nger -Tutorial
Technologie-Peripherieger?te
KI
Erstellen Sie Ihre erste LLM -Anwendung: Ein Anf?nger -Tutorial

Haben Sie jemals versucht, Ihr eigenes gro?es Sprachmodell (LLM) zu erstellen? Haben Sie sich jemals gefragt, wie Menschen ihre eigene LLM -Anwendung stellen, um ihre Produktivit?t zu steigern? LLM -Anwendungen haben sich in jeder Hinsicht als nützlich erwiesen. Der Aufbau einer LLM -App ist jetzt in der Reichweite eines jeden. Dank der Verfügbarkeit von KI -Modellen sowie leistungsstarken Frameworks. In diesem Tutorial werden wir unsere erste LLM -Bewerbung auf die so leistungsstarke Weise erstellen. Beginnen wir den Prozess. Wir werden jeden Prozess von Idee zu Code zu Code einzeln eingehen.
Inhaltsverzeichnis
- Warum LLM -Apps wichtig?
- Schlüsselkomponenten einer LLM -Anwendung
- Ausw?hlen der richtigen Werkzeuge
- Schritt -für -Schritt -Implementierung
- 1. Einrichten von Python und seiner Umgebung
- 2. Installieren der erforderlichen Abh?ngigkeiten
- 1. Importieren aller Abh?ngigkeiten
- 4. Umgebungsaufbau
- 5. Agent Setup
- 6. Stromlit UI
- 7. Ausführen der Anwendung
- Abschluss
- H?ufig gestellte Fragen
Warum LLM -Apps wichtig?
LLM -Anwendungen sind insofern einzigartig, als sie natürliche Sprache verwenden, um den Benutzer zu verarbeiten und auch in natürlicher Sprache zu reagieren. Darüber hinaus sind LLM -Apps den Kontext der Benutzerabfrage kennen und entsprechend beantworten. H?ufige Anwendungsf?lle von LLM -Anwendungen sind Chatbots, Inhaltsgenerierung und Q & A -Agenten. Es wirkt sich erheblich auf die Benutzererfahrung aus, indem es die Konversations -KI, den Treiber der heutigen KI -Landschaft, einbezieht.
Schlüsselkomponenten einer LLM -Anwendung
Das Erstellen einer LLM -Anwendung umfasst Schritte, in denen wir verschiedene Komponenten der LLM -Anwendung erstellen. Am Ende verwenden wir diese Komponenten, um eine vollwertige Anwendung zu erstellen. Lassen Sie uns von ihnen nacheinander erfahren, um eine vollst?ndige Verst?ndnis jeder Komponente gründlich zu erhalten.
- Grundmodell: Dies beinhaltet die Auswahl Ihres grundlegenden KI -Modells oder LLM, das Sie in Ihrer Anwendung im Backend verwenden. Betrachten Sie dies als das Gehirn Ihrer Anwendung.
- Prompt Engineering: Dies ist die wichtigste Komponente, die Ihrem LLM -Kontext über Ihre Anwendung verleiht. Dies beinhaltet das Definieren des Tons, der Pers?nlichkeit und der Pers?nlichkeit Ihres LLM, damit er entsprechend antworten kann.
- Orchestrierungsschicht: Frameworks wie Langchain, Llamaindex fungieren als Orchestrierungsschicht, die alle LLM -Anrufe und Ausgaben für Ihre Anwendung abwickelt. Diese Frameworks binden Ihre Anwendung mit LLM, damit Sie einfach auf AI -Modelle zugreifen k?nnen.
- Tools: Tools fungieren als wichtigste Komponente beim Erstellen Ihrer LLM -App. Diese Tools werden h?ufig von LLMs verwendet, um Aufgaben auszuführen, die KI -Modelle nicht direkt ausführen k?nnen.
Ausw?hlen der richtigen Werkzeuge
Die Auswahl der richtigen Tools ist eine der wichtigsten Aufgaben zum Erstellen einer LLM -Anwendung. Menschen überspringen diesen Teil des Prozesses h?ufig und beginnen mit der Erstellung einer LLM -Anwendung von Grund auf mit allen verfügbaren Tools. Dieser Ansatz ist sehr vage. Man sollte Tools effizient definieren, bevor man in die Entwicklungsphase eingeht. Lassen Sie unsere Werkzeuge definieren.
- Auswahl eines LLM: Ein LLM fungiert als Geist hinter Ihrer Bewerbung. Die Auswahl des richtigen LLM ist ein entscheidender Schritt, bei dem die Kosten- und Verfügbarkeitsparameter im Auge behalten. Sie k?nnen LLMs von OpenAI, COQ und Google verwenden. Sie müssen einen API -Schlüssel von ihrer Plattform sammeln, um diese LLMs zu verwenden.
- Frameworks: Die Frameworks fungieren als Integration zwischen Ihrer Anwendung und der LLM. Es hilft uns bei der Vereinfachung der Eingabeaufforderungen an die LLM, die Logik verkettet, die den Workflow der Anwendung definiert. Es gibt Frameworks wie Langchain und Llamaindex, die h?ufig zur Erstellung einer LLM -Anwendung verwendet werden. Langchain gilt als der anf?ngerfreundlichste und am einfachsten zu bedienende.
- Front-End-Bibliotheken: Python bietet gute Unterstützung für das Erstellen von Front-End für Ihre Anwendungen im minimalen Code. Bibliotheken wie Streamlit, Gradio und Chainlit verfügen über Funktionen, um Ihrer LLM -Anwendung ein sch?nes Frontend mit minimalem Code zu verleihen.
Schritt -für -Schritt -Implementierung
Wir haben alle grundlegenden Voraussetzungen für den Bau unserer LLM -Anwendung behandelt. überlegen wir uns auf die tats?chliche Implementierung und schreiben Sie den Code für die Entwicklung der LLM -Anwendung von Grund auf neu. In diesem Handbuch erstellen wir eine LLM-Anwendung, die eine Abfrage als Eingabe aufnimmt, die Abfrage in Unterparts unterteilt, das Internet durchsucht und das Ergebnis dann in einen gut aussehenden Markdown-Bericht mit den verwendeten Referenzen kompiliert.
1. Einrichten von Python und seiner Umgebung
Der erste Schritt besteht darin, den Python -Dolmetscher von seiner offiziellen Website herunterzuladen und auf Ihrem System zu installieren. Vergessen Sie nicht, w?hrend der Installation die Pfadvariable hinzufügen zur Systemoption hinzufügen.
Stellen Sie au?erdem sicher, dass Sie Python installiert haben, indem Sie Python in die Befehlszeile eingeben.
2. Installieren der erforderlichen Abh?ngigkeiten
Dieser Schritt installiert die Bibliotheksabh?ngigkeiten in Ihr System. ?ffnen Sie Ihr Terminal und geben Sie den folgenden Befehl ein, um die Abh?ngigkeiten zu installieren.
PIP Installation stromlit dotenv Langchain Langchain-Openai Langchain-Community Langchain-Core
In diesem Befehl wird das Terminal ausgeführt und alle Abh?ngigkeiten für das Ausführen unserer Anwendung installiert.
1. Importieren aller Abh?ngigkeiten
Gehen Sie nach der Installation der Abh?ngigkeiten zu einem IDE -Code -Editor wie dem VS -Code und ?ffnen Sie sie im erforderlichen Pfad. Erstellen Sie nun eine Python -Datei "app.py" und fügen Sie die folgenden Importanweisungen in die Datei ein
importieren stromlit als st OS importieren aus dotenv import load_dotenv aus Langchain_openai importieren Sie Chatopenai von Langchain_Community.tools.tavily_search importieren tavilysearchResults von Langchain.agents importieren agentenexecutor create_tool_calling_agent von Langchain_core.Prompts importieren ChatpromptTemplate, MessagePlaceHolder von Langchain_core.Messages Import Aimessage, HumanMessage
4. Umgebungsaufbau
Wir erstellen einige Umgebungsvariablen für unsere LLM und andere Tools. Erstellen Sie hierzu eine Datei ".env" im selben Verzeichnis und fügen Sie mit den Umgebungsvariablen API -Tasten hinein. In unserer LLM-Anwendung werden wir beispielsweise zwei API-Schlüssel verwenden: einen OpenAI-API-Schlüssel für unsere LLM, auf die von hier aus zugegriffen werden kann, und auf einen Tavily-API-Schlüssel, mit dem das Internet in Echtzeit gesucht werden kann, auf die von hier aus zugegriffen werden kann.
Openai_api_key = "your_api_key" Tavily_api_key = "your_api_key"
Schreiben Sie nun in Ihrer App.py den folgenden Code. Dieser Code l?dt alle verfügbaren Umgebungsvariablen direkt in Ihre Arbeitsumgebung.
# --- Umgebungsaufbau ---
load_dotenv ()
Openai_api_key = os.getenv ("openai_api_key")
Tavily_api_key = os.getenv ("tavily_api_key")
wenn nicht openai_api_key:
St.Error ("? OpenAI-API-Schlüssel nicht gefunden. Bitte setzen Sie es in Ihrer .env-Datei (OpenAI_API_KEY = 'SK -...')").
Wenn nicht tavily_api_key:
St.Error ("? Tavily API-Schlüssel nicht gefunden. Bitte setzen Sie es in Ihre .env-Datei (Tavily_API_Key = 'TVly -...')").
Wenn nicht openai_api_key oder nicht tavily_api_key:
St.Stop ()
5. Agent Setup
Da haben wir alle Umgebungsvariablen geladen. Lassen Sie uns den Agenten -Workflow erstellen, den jede Abfrage w?hrend der Verwendung der LLM -Anwendung durchlaufen würde. Hier erstellen wir ein Tool, dh tavily suchen, das das Internet durchsucht. Ein Agent Executor, der den Agenten mit Tools ausführt.
# --- Agent Setup ---
@St.Cache_Resource
Def get_agent_executor ():
"" "
Initialisiert und gibt den Langchain Agent Executor initialisiert und gibt zurück.
"" "
# 1. Definieren Sie die LLM
llm = chatopenai (model = "gpt-4o-mini", Temperatur = 0,2, api_key = openai_api_key)
# 2. Definieren Sie Tools (vereinfachte Deklaration)
Werkzeuge = [
TavilySearchResults (
max_results = 7,
name = "web_search",
api_key = tavily_api_key,
Beschreibung = "führt Websuche durch, um aktuelle Informationen zu finden."
)
]
# 3.. Aktualisierte Eingabeaufforderung Vorlage (v0.3 Best Practices)
prompt_template = chatpromptTemplate.from_messages (
[
("System", "" "
Sie sind eine Weltklasse-KI. Geben Sie umfassende, genaue Antworten mit Markdown -Zitaten an.
Verfahren:
1. Dekompeten Sie Fragen in Unterausfragen dekompetenz
2. Verwenden Sie für jedes Unterbild `web_search`
3.. Informationen synthetisieren
4. Zitieren Sie Quellen mit Markdown -Fu?noten
5. Referenzliste einschlie?en
Follow-up-Fragen sollten den Chat-Historie-Kontext verwenden.
"" "),
MessagePlaPleholder ("chat_history", optional = true),
("Mensch", "{Eingabe}"),
MessagePlacePlader ("Agent_Scratchpad"),
]
)
# 4.. Agent erstellen (aktualisiert auf create_tool_calling_agent)
Agent = create_tool_calling_agent (LLM, Tools, Eingabeaufforderung_Template)
# 5. AgentExecutor mit moderner Konfiguration
RETUCT agierexecutor (
Agent = Agent,
Werkzeuge = Werkzeuge,
w?rtlich = wahr,
handle_paring_errors = true,
max_iterations = 10,
return_intermediate_steps = true
)
Hier verwenden wir eine schnelle Vorlage, die den GPT-4O-Mini-LLM leitet, wie der Suchenteil durchzuführen, den Bericht mit Referenzen kompiliert. Dieser Abschnitt ist für alle Backend -Arbeiten Ihrer LLM -Anwendung verantwortlich. Alle ?nderungen in diesem Abschnitt wirken sich direkt auf die Ergebnisse Ihrer LLM -Anwendung aus.
6. Stromlit UI
Wir haben die gesamte Backend -Logik für unsere LLM -Anwendung eingerichtet. Lassen Sie uns nun die Benutzeroberfl?che für unsere Bewerbung erstellen, die für die Frontend -Ansicht unserer Bewerbung verantwortlich ist.
# --- Stromlit UI ---
St.Set_Page_Config (page_title = "AI Research Agent?", Page_icon = "?", Layout = "Wide").
St.Markdown ("" "
<style>
???.stChatMessage {
???????border-radius: 10px;
???????padding: 10px;
???????margin-bottom: 10px;
???}
???.stChatMessage.user {
???????background-color: #E6F3FF;
???}
???.stChatMessage.assistant {
???????background-color: #F0F0F0;
???}
???</style>
"" ", unafe_allow_html = true)
St.Title ("? AI Research Agent")
St.Kaption ("Ihr erweiterter KI -Assistent, um das Web zu durchsuchen, Informationen zu synthetisieren und zitierte Antworten zu geben.")
Wenn "chat_history" nicht in St.Session_State:
St.Session_State.chat_history = []
Für Message_OBJ in St.Session_State.chat_history:
Rollen = "Benutzer" if isinstance (message_obj, humanmessage) sonst "Assistant"
mit St.Chat_Message (Rolle):
St.Markdown (Message_OBJ.Content)
user_query = st.chat_input ("eine Forschungsfrage stellen ...")
Wenn user_query:
St.Session_State.chat_history.Append (HumanMessage (content = user_query)))
mit St.Chat_Message ("Benutzer"):
St.Markdown (User_query)
mit St.Chat_Message ("Assistant"):
mit St.spinner ("? Denken & recherchieren ..."):
versuchen:
Agent_executor = get_agent_executor ()
response = Agent_executor.invoke ({{
"Eingabe": user_query,
"chat_history": St.Session_state.chat_history [:-1]
})
Antwort = Antwort ["Ausgabe"]
St.Session_State.chat_history.Append (AIMESSAGE (Content = Antwort))
St.Markdown (Antwort)
au?er Ausnahme als E:
ERROR_MESSAGE = F "Entschuldigung ist ein Fehler aufgetreten: {str (e)}"
St.Error (ERROR_MESSAGE)
print (f "Fehler w?hrend des Agentenaufrufs: {e}")
In diesem Abschnitt definieren wir den Titel, die Beschreibung und den Chat -Historium unserer Anwendung. Streamlit bietet eine Menge Funktionen für das Anpassen unserer Anwendung. Wir haben hier eine begrenzte Anzahl von Anpassungsoptionen verwendet, um unsere Anwendung weniger komplex zu machen. Sie k?nnen Ihre Bewerbung an Ihre Anforderungen anpassen.
7. Ausführen der Anwendung
Wir haben alle Abschnitte für unsere Bewerbung definiert, und jetzt ist es bereit für den Start. Lassen Sie uns visuell sehen, was wir erstellt haben, und die Ergebnisse analysieren.
?ffnen Sie Ihr Terminal und Ihren Typ
streamlit run app.py
Dadurch wird Ihre Anwendung initialisiert und Sie werden in Ihren Standardbrowser umgeleitet.
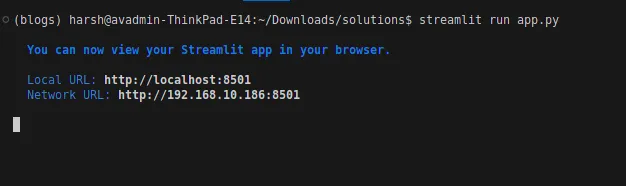
Dies ist die Benutzeroberfl?che Ihrer LLM -Anwendung:
Versuchen wir, unsere LLM -Anwendung zu testen
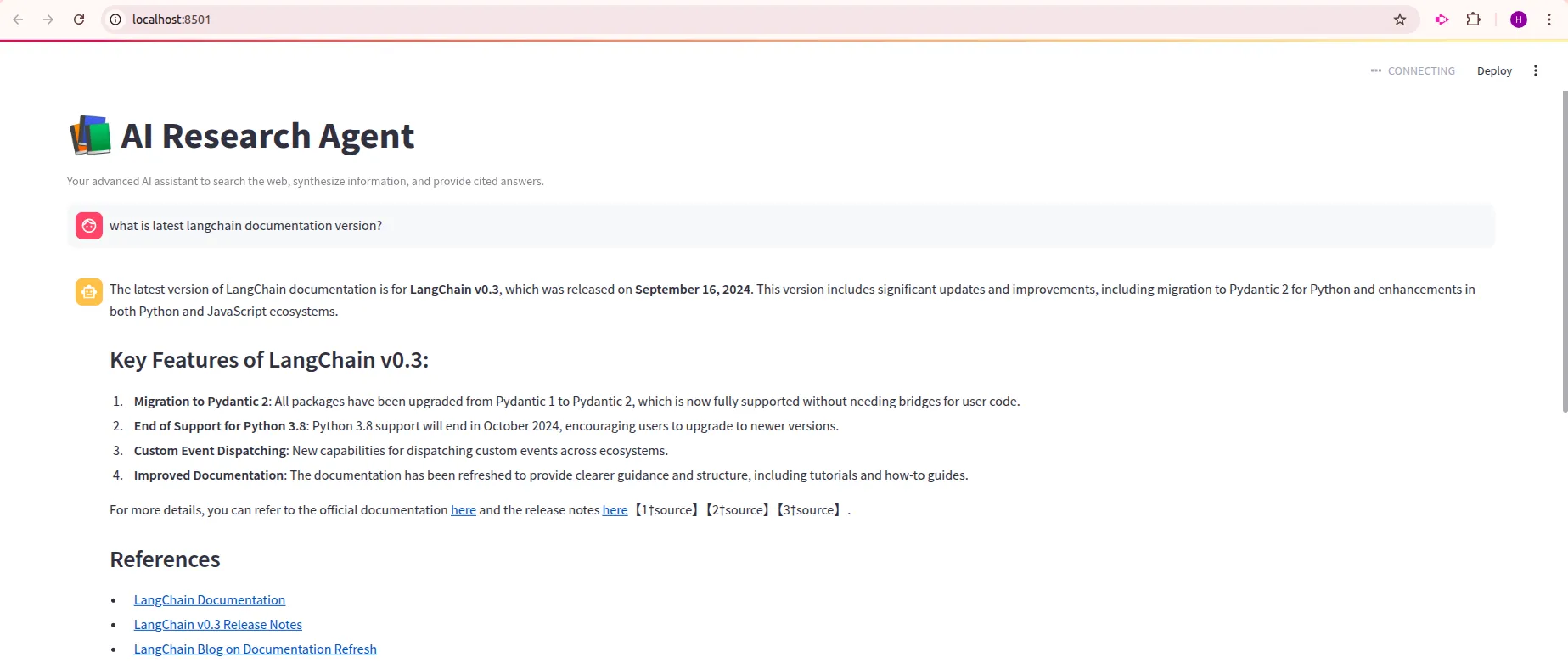
Abfrage : "Was ist die neueste Langchain -Dokumentationsversion?"
Abfrage : "Wie ver?ndert Langchain das KI -Spiel?"
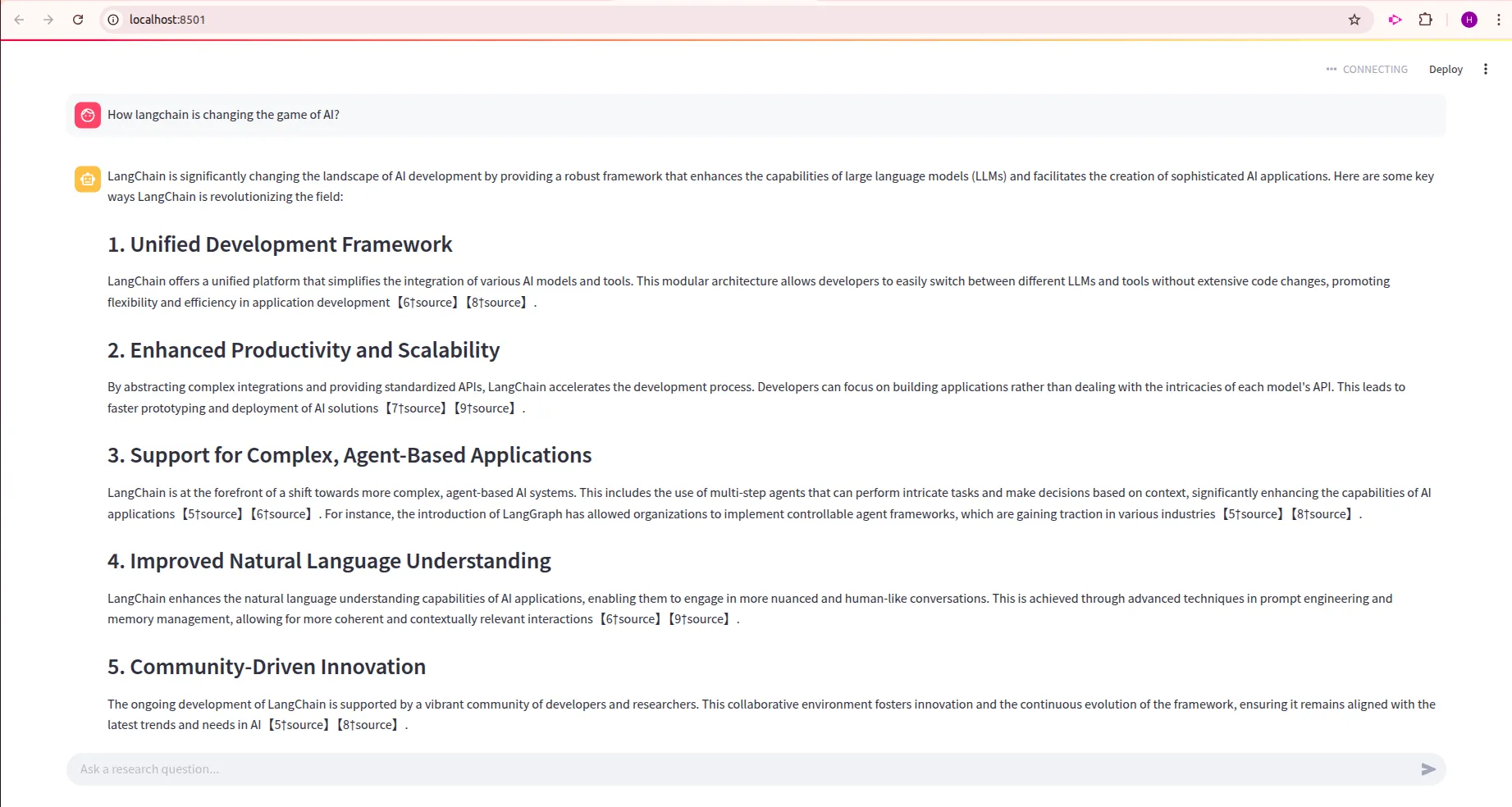
Aus den Ausg?ngen k?nnen wir feststellen, dass unsere LLM -Anwendung die erwarteten Ergebnisse zeigt. Detaillierte Ergebnisse mit Referenzlinks. Jeder kann auf diese Referenzlinks klicken, um auf den Kontext zuzugreifen, aus dem unser LLM die Frage beantwortet. Daher haben wir unsere erste LLM-Anwendung erfolgreich erstellt. Fühlen Sie sich frei, ?nderungen in diesem Code vorzunehmen und einige komplexere Anwendungen zu erstellen, wobei dieser Code als Referenz genommen wird.
Abschluss
Das Erstellen von LLM -Anwendungen ist einfacher als je zuvor. Wenn Sie dies lesen, bedeutet dies, dass Sie über genügend Wissen verfügen, um Ihre eigenen LLM -Anwendungen zu erstellen. In diesem Handbuch haben wir die Umgebung eingerichtet, die Code, die Agentenlogik, die App -Benutzeroberfl?che definiert und diese auch in eine streamlitische Anwendung umgewandelt. Dies deckt alle wichtigen Schritte bei der Entwicklung einer LLM -Anwendung ab. Versuchen Sie, mit schnellen Vorlagen, LLM -Ketten und UI -Anpassungen zu experimentieren, um Ihre Anwendung entsprechend Ihren Anforderungen personalisiert zu machen. Es ist nur der Anfang; Reichere KI-Workflows warten auf Sie, mit Agenten, Speicher und dom?nenspezifischen Aufgaben.
H?ufig gestellte Fragen
Q1. Muss ich ein Modell von Grund auf neu trainieren?A. Nein, Sie k?nnen mit vorgebildeten LLMs (wie GPT- oder Open-Source-Unternehmen) beginnen und sich auf ein schnelles Design und die App-Logik konzentrieren.
Q2. Warum Frameworks wie Langchain verwenden?A. Sie vereinfachen die Erh?hungsaufforderungen, den Umgang mit Speicher und die Integration von Werkzeugen, ohne das Rad neu zu erfinden.
Q3. Wie kann ich Konversationsged?chtnis hinzufügen?A. Verwenden Sie Pufferspeicherklassen in Frameworks (z. B. Langchain) oder integrieren Sie Vektordatenbanken zum Abrufen.
Q4. Was ist Rag und warum benutze es?A. Retrieval-Augmented-Generation bringt externe Daten in den Kontext des Modells und verbessert die Reaktionsgenauigkeit auf dom?nenspezifischen Abfragen.
Q5. Wo kann ich meine LLM -App bereitstellen?A. Beginnen Sie mit einer lokalen Demo mit Gradio und skalieren Sie dann mit den umarmenden Gesichtsr?umen, der optimalen Cloud-, Heroku-, Docker- oder Cloud -Plattformen.
Das obige ist der detaillierte Inhalt vonErstellen Sie Ihre erste LLM -Anwendung: Ein Anf?nger -Tutorial. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Hei?e KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem v?llig kostenlosen KI-Gesichtstausch-Tool aus!

Hei?er Artikel
Hei?e Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Kimi K2: Das m?chtigste Open-Source-Agentenmodell
Jul 12, 2025 am 09:16 AM
Kimi K2: Das m?chtigste Open-Source-Agentenmodell
Jul 12, 2025 am 09:16 AM
Erinnern Sie sich an die Flut chinesischer Open-Source-Modelle, die die Genai-Industrie Anfang dieses Jahres gest?rt haben? W?hrend Deepseek die meisten Schlagzeilen machte, war Kimi K1.5 einer der herausragenden Namen in der Liste. Und das Modell war ziemlich cool.
 Grok 4 gegen Claude 4: Was ist besser?
Jul 12, 2025 am 09:37 AM
Grok 4 gegen Claude 4: Was ist besser?
Jul 12, 2025 am 09:37 AM
Bis Mitte 2025 heizt sich das KI ?Wettret“ auf, und Xai und Anthropic haben beide ihre Flaggschiff-Modelle GROK 4 und Claude 4 ver?ffentlicht. Diese beiden Modelle befinden
 10 erstaunliche humanoide Roboter, die heute bereits unter uns gehen
Jul 16, 2025 am 11:12 AM
10 erstaunliche humanoide Roboter, die heute bereits unter uns gehen
Jul 16, 2025 am 11:12 AM
Aber wir müssen wahrscheinlich nicht einmal 10 Jahre warten, um einen zu sehen. Was als erste Welle wirklich nützlicher, menschlicher Maschinen angesehen werden k?nnte, ist bereits da. In den letzten Jahren wurden eine Reihe von Prototypen und Produktionsmodellen aus t herausgezogen
 Context Engineering ist der neue ' Schnelltechnik
Jul 12, 2025 am 09:33 AM
Context Engineering ist der neue ' Schnelltechnik
Jul 12, 2025 am 09:33 AM
Bis zum Vorjahr wurde eine schnelle Engineering als entscheidende F?higkeit zur Interaktion mit gro?artigen Modellen (LLMs) angesehen. In jüngster Zeit sind LLM jedoch in ihren Argumentations- und Verst?ndnisf?higkeiten erheblich fortgeschritten. Natürlich unsere Erwartung
 Leia's Imgsitary Mobile App bringt die 3D -Tiefe in allt?gliche Fotos
Jul 09, 2025 am 11:17 AM
Leia's Imgsitary Mobile App bringt die 3D -Tiefe in allt?gliche Fotos
Jul 09, 2025 am 11:17 AM
Aufgebaut auf Leia's propriet?rer neuronaler Tiefenmotor verarbeitet die App still Bilder und fügt die natürliche Tiefe zusammen mit simulierten Bewegungen hinzu - wie Pfannen, Zoome und Parallaxeffekte -, um kurze Video -Rollen zu erstellen, die den Eindruck erwecken, in die SCE einzusteigen
 Was sind die 7 Arten von AI -Agenten?
Jul 11, 2025 am 11:08 AM
Was sind die 7 Arten von AI -Agenten?
Jul 11, 2025 am 11:08 AM
Stellen Sie sich vor, dass etwas Geformtes, wie ein KI -Motor, der bereit ist, ein detailliertes Feedback zu einer neuen Kleidungssammlung von Mailand oder automatische Marktanalyse für ein weltweit betriebenes Unternehmen zu geben, oder intelligentes Systeme, das eine gro?e Fahrzeugflotte verwaltet.
 Diese KI -Modelle haben nicht die Sprache gelernt, sie lernten Strategie
Jul 09, 2025 am 11:16 AM
Diese KI -Modelle haben nicht die Sprache gelernt, sie lernten Strategie
Jul 09, 2025 am 11:16 AM
Eine neue Studie von Forschern am King's College London und der University of Oxford teilt die Ergebnisse dessen, was passiert ist, als OpenAI, Google und Anthropic in einem Cutthroat -Wettbewerb zusammengeworfen wurden, der auf dem iterierten Dilemma des Gefangenen basiert. Das war nein
 Versteckte Befehlskrise: Forscher Game KI, um ver?ffentlicht zu werden
Jul 13, 2025 am 11:08 AM
Versteckte Befehlskrise: Forscher Game KI, um ver?ffentlicht zu werden
Jul 13, 2025 am 11:08 AM
Wissenschaftler haben eine clevere, aber alarmierende Methode aufgedeckt, um das System zu umgehen. Juli 2025 markierte die Entdeckung einer aufw?ndigen Strategie, bei der Forscher unsichtbare Anweisungen in ihre akademischen Einreichungen eingefügt haben - diese verdeckten Richtlinien waren Schwanz
