

Was sind die am h?ufigsten verwendeten Datenstrukturen in Java?
Apr 14, 2021 pm 04:52 PM
Zu den Java-Datenstrukturen geh?ren: 1. Array; 2. Verknüpfte Liste, eine rekursive Datenstruktur; 3. Stapel, der Daten nach den Prinzipien ?Last In, First Out“ speichert; . Warteschlange; 5. Ein Baum ist eine Sammlung hierarchischer Beziehungen, die aus n (n>0) begrenzten Knoten besteht. 7. Diagramm;

Die Betriebsumgebung dieses Tutorials: Windows7-System, Java8-Version, DELL G3-Computer.
Gemeinsame Datenstrukturen in Java
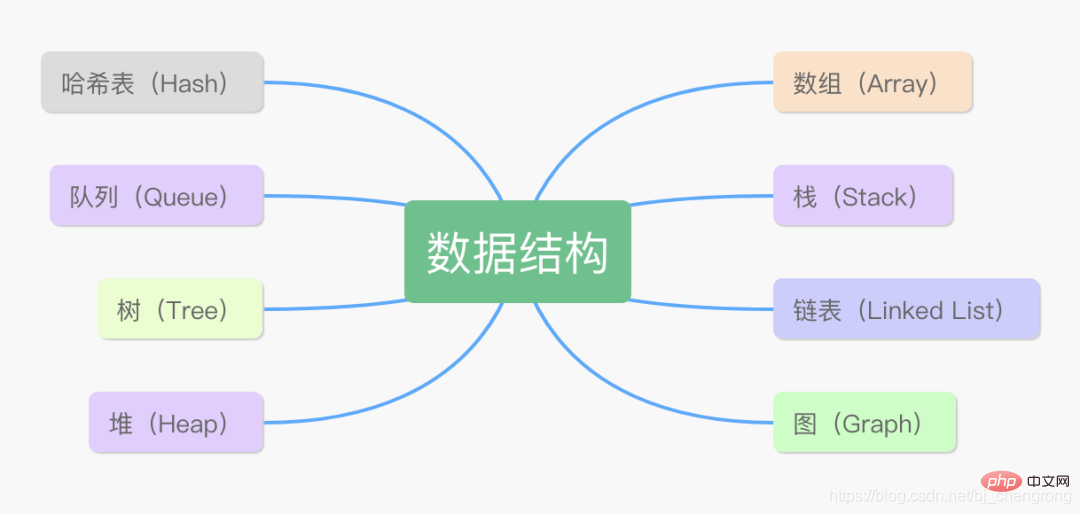
Was sind die Unterschiede zwischen diesen 8 Datenstrukturen?
①, Array
Vorteile:
Das Abfragen von Elementen nach Index ist schnell;
Es ist auch praktisch, das Array nach Index zu durchlaufen.
Nachteile:
Die Gr??e des Arrays wird nach der Erstellung festgelegt und kann nicht erweitert werden.
Arrays k?nnen nur einen Datentyp speichern.
Die Vorg?nge zum Hinzufügen und L?schen von Elementen sind zeitaufw?ndig -aufw?ndig, da andere Elemente verschoben werden müssen.
②, verknüpfte Liste
-
Das Buch ?Algorithmus (4. Auflage)“ definiert eine verknüpfte Liste wie folgt:
Die verknüpfte Liste ist eine rekursive Datenstruktur, sie ist entweder leer (null), Oder ein Verweis auf einen Knoten, der auch ein Element enth?lt, und ein Verweis auf eine andere verknüpfte Liste.
Die LinkedList-Klasse von Java kann die Struktur einer verknüpften Liste sehr anschaulich in Form von Code ausdrücken:
public class LinkedList<E> {
transient Node<E> first;
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}Dies ist eine doppelt verknüpfte Liste. Das aktuelle Elementelement hat sowohl prev als auch next, aber das prev von first ist null und next of last ist null. Wenn es sich um eine einseitig verknüpfte Liste handelt, gibt es nur next und kein prev.
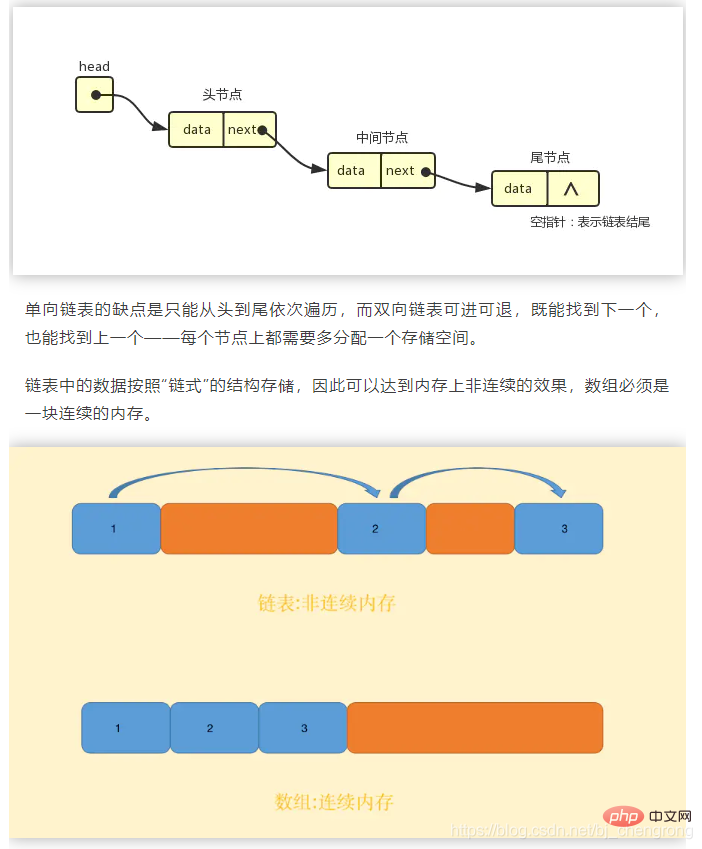
Da die verknüpfte Liste nicht sequentiell gespeichert werden muss, kann sie beim Einfügen und L?schen eine O(1)-Zeitkomplexit?t erreichen (Sie müssen nur die Referenz erneut verweisen, und das ist nicht der Fall müssen andere Elemente wie ein Array verschieben). Darüber hinaus überwindet die verknüpfte Liste auch den Nachteil des Arrays, dass die Datengr??e im Voraus bekannt sein muss, und erm?glicht so eine flexible dynamische Speicherverwaltung.
Vorteile:
Keine Notwendigkeit, die Kapazit?t zu initialisieren;
Sie k?nnen jedes Element hinzufügen;
Aktualisieren Sie die Referenz nur beim Einfügen und L?schen.
Nachteile:
enth?lt eine gro?e Anzahl von Referenzen und nimmt viel Speicherplatz ein;
Das Suchen von Elementen erfordert das Durchlaufen der gesamten verknüpften Liste, was zeitaufw?ndig ist.
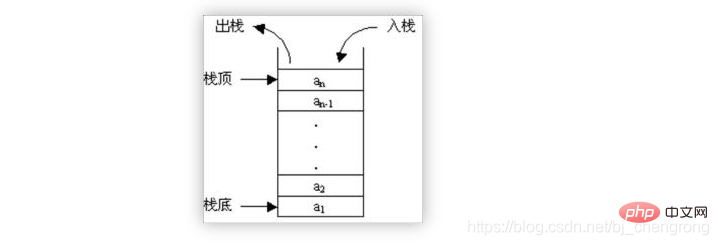
③, Stapel
Stapel ist wie ein Eimer, der Boden ist versiegelt und die Oberseite ist offen, Wasser kann ein- und austreten. Freunde, die Eimer benutzt haben, sollten dieses Prinzip verstehen: Das Wasser, das zuerst hineinflie?t, befindet sich am Boden des Eimers, und das Wasser, das sp?ter hineinflie?t, befindet sich oben im Eimer. Das Wasser, das zuletzt hineinflie?t, wird zuerst ausgegossen. und das Wasser, das zuerst einstr?mt, wird zuletzt ausgegossen.
In ?hnlicher Weise speichert der Stapel Daten nach den Prinzipien ?Zuletzt rein, zuerst raus“ und ?Zuerst rein, zuletzt raus“. Wenn die Daten ausgelesen werden, werden sie nacheinander gelesen.
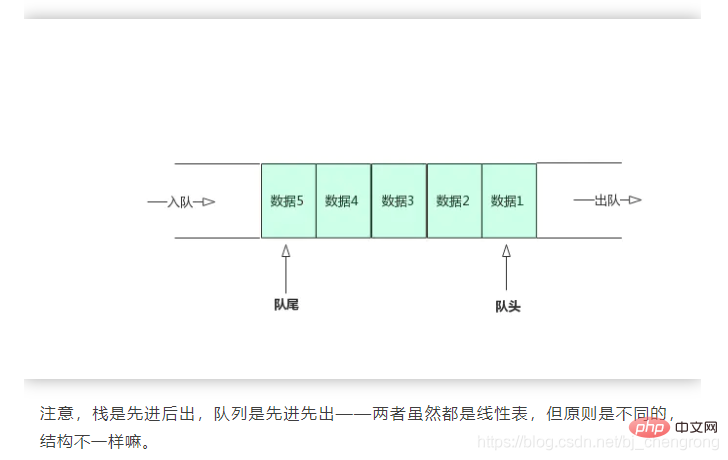
④, Warteschlange
Die Warteschlange ist wie ein Abschnitt einer Wasserleitung, bei der beide Enden offen sind, Wasser flie?t an einem Ende ein und kommt dann am anderen Ende wieder heraus. Das Wasser, das zuerst einstr?mt, kommt zuerst heraus, und das Wasser, das zuletzt einstr?mt, kommt zuletzt heraus.
Etwas anders als die Wasserleitung definiert die Warteschlange zwei Enden, ein Ende wird als Anführer der Warteschlange und das andere Ende als Ende der Warteschlange bezeichnet. Der Kopf der Warteschlange erlaubt nur L?schvorg?nge (Dequeue), und der Schwanz der Warteschlange erlaubt nur Einfügevorg?nge (Enqueue).
⑤, Baum
Der Baum ist eine typische nichtlineare Struktur, bei der es sich um eine Reihe hierarchischer Beziehungen handelt, die aus n (n>0) begrenzten Knoten bestehen.
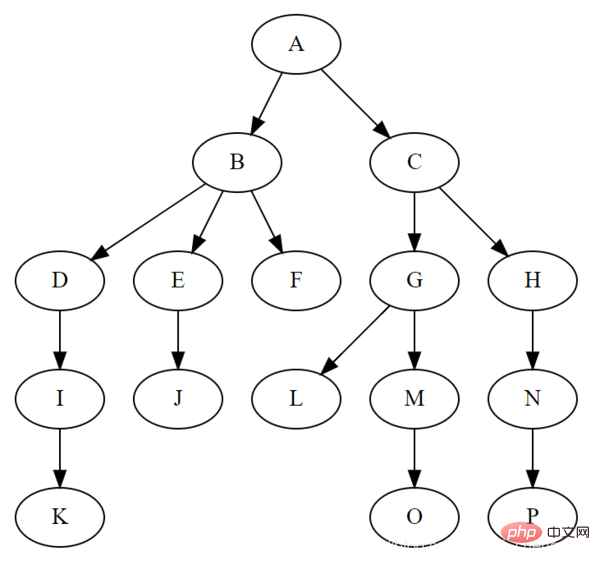
Der Grund, warum es ?Baum“ genannt wird, liegt darin, dass diese Datenstruktur wie ein umgedrehter Baum aussieht, au?er dass die Wurzeln oben und die Bl?tter unten sind. Die Baumdatenstruktur weist die folgenden Merkmale auf:
Jeder Knoten hat nur eine begrenzte Anzahl untergeordneter Knoten oder keine untergeordneten Knoten.
Ein Knoten ohne übergeordneten Knoten wird als Wurzelknoten bezeichnet hat Und es gibt nur einen übergeordneten Knoten;
Mit Ausnahme des Wurzelknotens kann jeder untergeordnete Knoten in mehrere disjunkte Teilb?ume unterteilt werden.
-
Das Bild unten zeigt einige Begriffe für B?ume:
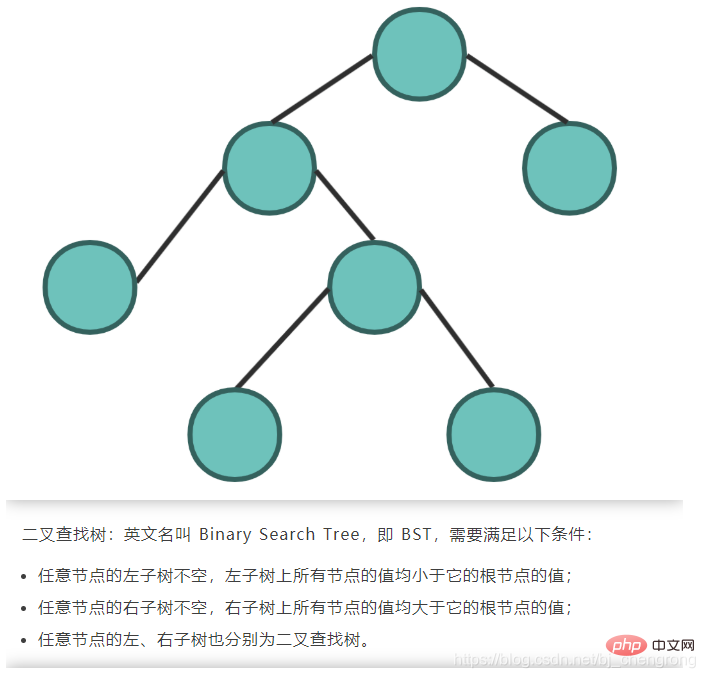
Basierend auf den Eigenschaften des bin?ren Suchbaums besteht sein Vorteil gegenüber anderen Datenstrukturen darin, dass die zeitliche Komplexit?t von Suche und Einfügung gering ist, was O (logn) ist. Wenn wir 5 Elemente aus dem obigen Bild finden m?chten, beginnen wir mit dem Wurzelknoten 7. Wenn wir 5 finden, muss es links von 7 sein. Wenn wir 4 finden, muss 5 rechts von 4 sein. Wenn wir finden 6, dann muss 5 links von 6 sein. Seite, gefunden. Idealerweise kann durch die Suche nach Knoten über BST die Anzahl der zu überprüfenden Knoten halbiert werden.
Idealerweise kann durch die Suche nach Knoten über BST die Anzahl der zu überprüfenden Knoten halbiert werden. Ausgewogener Bin?rbaum: Ein Bin?rbaum genau dann, wenn der H?henunterschied zwischen den beiden Teilb?umen eines Knotens nicht gr??er als 1 ist. Der von den ehemaligen sowjetischen Mathematikern Adelse-Velskil und Landis 1962 vorgeschlagene hochbalancierte Bin?rbaum wird nach dem englischen Namen der Wissenschaftler auch AVL-Baum genannt.
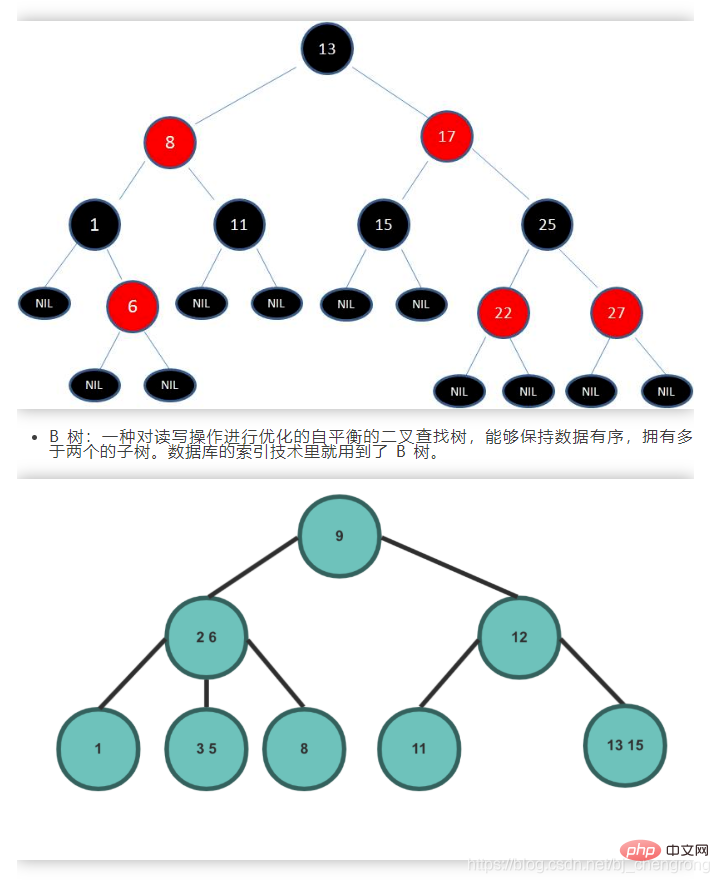
Ein ausgeglichener Bin?rbaum ist im Wesentlichen ein bin?rer Suchbaum. Um jedoch den H?henunterschied zwischen dem linken und dem rechten Teilbaum zu begrenzen und Situationen wie schiefe B?ume zu vermeiden, die dazu neigen, sich zu linearen Strukturen zu entwickeln, werden jeweils der linke und rechte Teilbaum verwendet Knoten im bin?ren Suchbaum Der H?henunterschied zwischen dem linken und dem rechten Teilbaum wird als Ausgleichsfaktor bezeichnet. Der Absolutwert des Ausgleichsfaktors jedes Knotens im Baum ist nicht gr??er als 1.Die Schwierigkeit beim Ausbalancieren eines Bin?rbaums besteht darin, das Links-Rechts-Gleichgewicht durch Links- oder Rechtsdrehung aufrechtzuerhalten, wenn Knoten gel?scht oder hinzugefügt werden. Der h?ufigste ausgeglichene Bin?rbaum in Java ist der Rot-Schwarz-Baum. Die Knoten sind rot oder schwarz. Das Gleichgewicht des Bin?rbaums wird durch Farbbeschr?nkungen aufrechterhalten:
1) Jeder Knoten kann nur rot oder schwarz sein 2) Wurzelknoten sind schwarz3) Jeder Blattknoten (NIL-Knoten, leerer Knoten) ist schwarz.
4) Wenn ein Knoten rot ist, sind beide untergeordneten Knoten schwarz. Das hei?t, zwei benachbarte rote Knoten dürfen nicht auf einem Pfad erscheinen. 5) Alle Pfade von jedem Knoten zu jedem seiner Bl?tter enthalten die gleiche Anzahl schwarzer Knoten.⑥, Heap
Der Heap kann als Array-Objekt eines Baums mit den folgenden Eigenschaften betrachtet werden:
Der Wert eines Knotens im Heap ist immer nicht gr??er oder kleiner als es Der Wert des übergeordneten Knotens;
Der Heap ist immer ein vollst?ndiger Bin?rbaum.
Der Heap mit dem gr??ten Wurzelknoten wird als maximaler Heap oder gro?er Wurzelheap bezeichnet, und der Heap mit dem kleinsten Wurzelknoten wird als minimaler Heap oder kleiner Wurzelheap bezeichnet.In einer linearen Struktur wird eine eindeutige lineare Beziehung zwischen Datenelementen erfüllt, und jedes Datenelement (au?er dem ersten und letzten) hat einen eindeutigen ?Vorg?nger“ und ?Nachfolger“
- In der Baumstruktur Es besteht eine offensichtliche hierarchische Beziehung zwischen Datenelementen, und jedes Datenelement bezieht sich nur auf ein Element (übergeordneter Knoten) in der oberen Ebene und mehrere Elemente (untergeordnete Knoten) in der unteren Ebene.
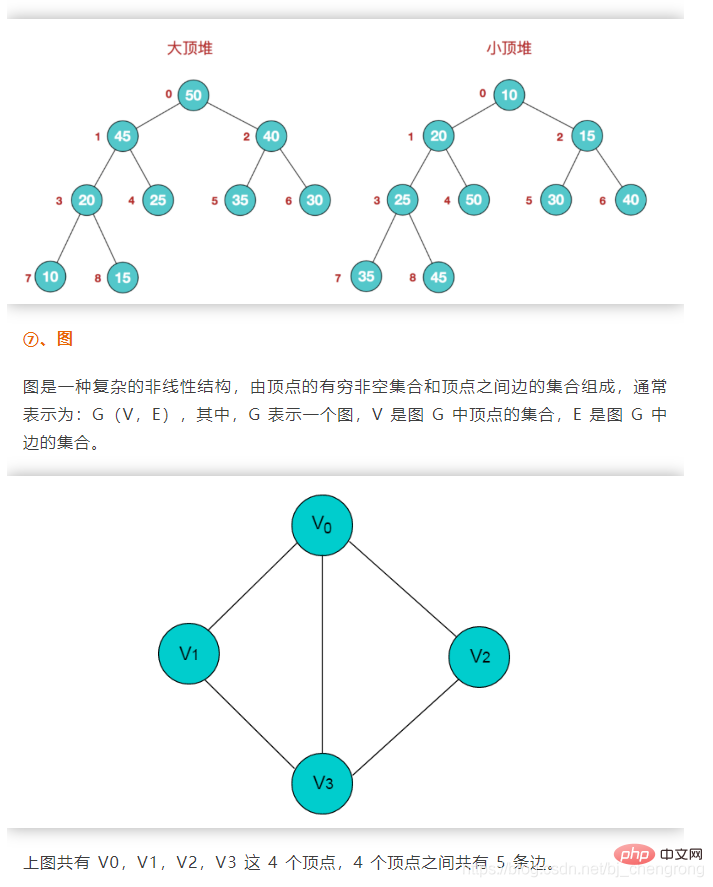
In der Diagrammstruktur ist die Beziehung zwischen Knoten ist willkürlich und zwei beliebige Datenelemente im Diagramm k?nnen in Beziehung stehen.
⑧, Hash-Tabelle
Hash-Tabelle, auch Hash-Tabelle genannt, ist eine Datenstruktur, auf die direkt über Schlüsselwerte zugegriffen werden kann. Die gr??te Funktion besteht darin, dass Suchen, Einfügen und L?schen schnell realisiert werden k?nnen.
Das gr??te Merkmal von Arrays ist, dass sie leicht zu durchsuchen, aber schwer einzufügen und zu l?schen sind. Im Gegensatz dazu ist die verknüpfte Liste schwer zu durchsuchen, aber leicht einzufügen und zu l?schen. Hash-Tabellen kombinieren perfekt die Vorteile beider. Javas HashMap fügt auf dieser Basis auch die Vorteile von B?umen hinzu.
Die Hash-Funktion spielt eine sehr wichtige Rolle in der Hash-Tabelle. Sie kann eine Eingabe beliebiger L?nge in eine Ausgabe fester L?nge umwandeln, und die Ausgabe ist der Hash-Wert. Die Hash-Funktion macht den Zugriffsprozess auf eine Datensequenz schneller und effizienter. Durch die Hash-Funktion k?nnen die Datenelemente schnell gefunden werden.
Wenn das Schlüsselwort k ist, wird sein Wert am Speicherort von
gespeichert. Daher kann der Wert, der k entspricht, direkt ohne Durchqueren erhalten werden.Für zwei beliebige Datenbl?cke ist die Wahrscheinlichkeit, dass ihre Hash-Werte gleich sind, ?u?erst gering. Das hei?t, es ist ?u?erst schwierig, für einen bestimmten Datenblock einen Datenblock mit demselben Hash-Wert zu finden. Darüber hinaus ist bei einem Datenblock die ?nderung des Hash-Werts sehr gro?, selbst wenn nur ein Bit davon ge?ndert wird – das ist der Wert von Hash!
Obwohl die Wahrscheinlichkeit ?u?erst gering ist, wird es dennoch vorkommen, dass Javas HashMap eine verknüpfte Liste an derselben Position im Array hinzufügt. Wenn die L?nge der verknüpften Liste gr??er als 8 ist, wird dies der Fall sein Zur Verarbeitung in einen rot-schwarzen Baum umgewandelt – Dies ist die sogenannte Zipper-Methode (Array + verknüpfte Liste).
Weitere Kenntnisse zum Thema Programmierung finden Sie unter: Programmiervideos! !
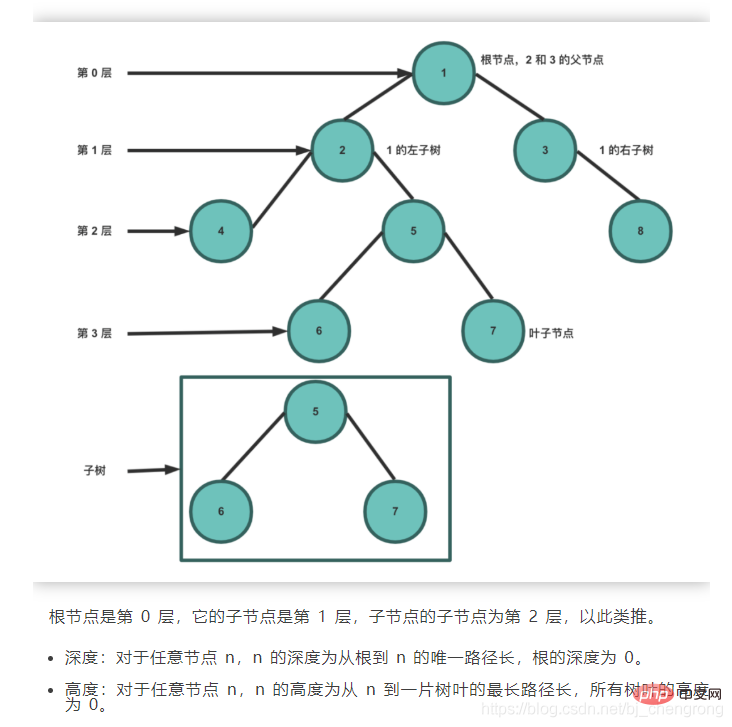 Idealerweise kann durch die Suche nach Knoten über BST die Anzahl der zu überprüfenden Knoten halbiert werden.
Idealerweise kann durch die Suche nach Knoten über BST die Anzahl der zu überprüfenden Knoten halbiert werden. 
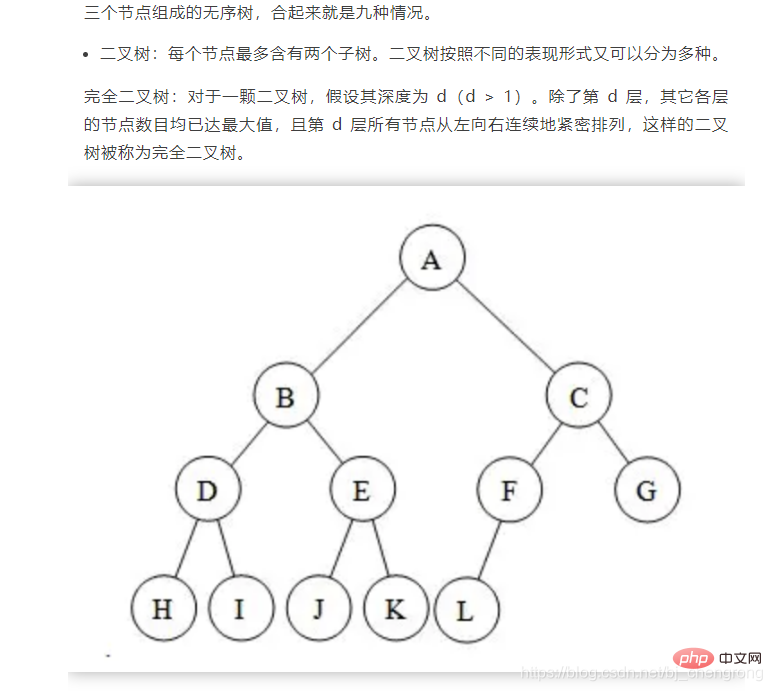 Die Schwierigkeit beim Ausbalancieren eines Bin?rbaums besteht darin, das Links-Rechts-Gleichgewicht durch Links- oder Rechtsdrehung aufrechtzuerhalten, wenn Knoten gel?scht oder hinzugefügt werden.
Die Schwierigkeit beim Ausbalancieren eines Bin?rbaums besteht darin, das Links-Rechts-Gleichgewicht durch Links- oder Rechtsdrehung aufrechtzuerhalten, wenn Knoten gel?scht oder hinzugefügt werden. 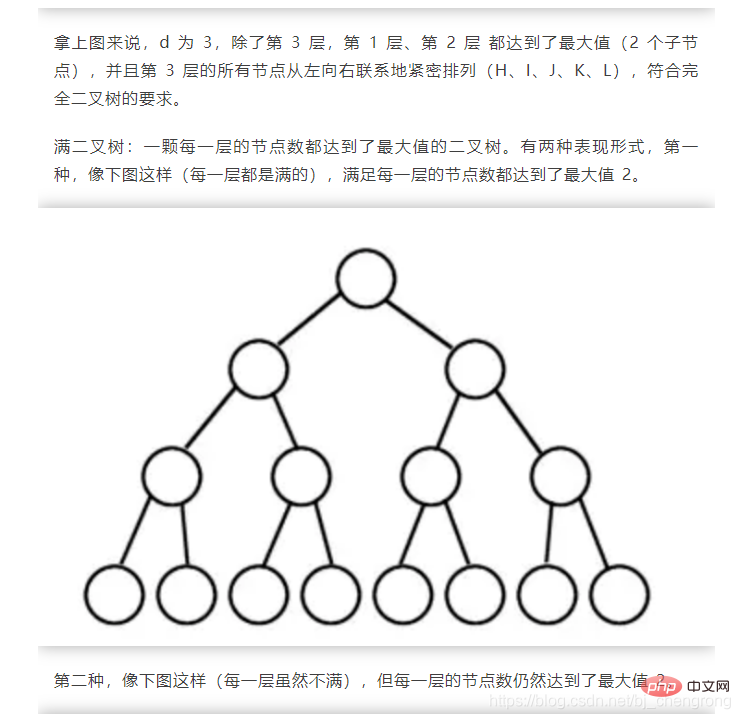
 2) Wurzelknoten sind schwarz
2) Wurzelknoten sind schwarz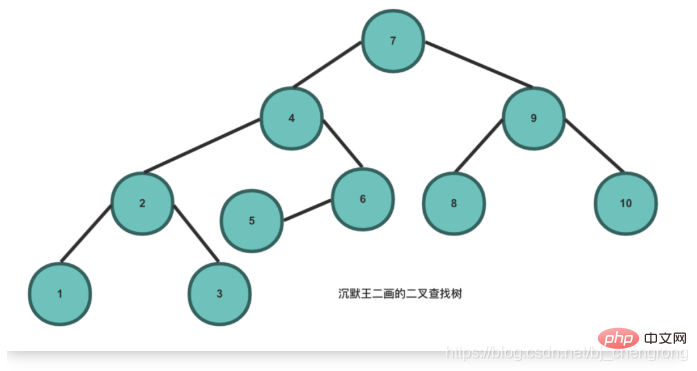
Das obige ist der detaillierte Inhalt vonWas sind die am h?ufigsten verwendeten Datenstrukturen in Java?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Hei?e KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem v?llig kostenlosen KI-Gesichtstausch-Tool aus!

Hei?er Artikel
Hei?e Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Wie gehe ich mit Transaktionen in Java mit JDBC um?
Aug 02, 2025 pm 12:29 PM
Wie gehe ich mit Transaktionen in Java mit JDBC um?
Aug 02, 2025 pm 12:29 PM
Um JDBC -Transaktionen korrekt zu verarbeiten, müssen Sie zun?chst den automatischen Komiti -Modus ausschalten und dann mehrere Vorg?nge ausführen und schlie?lich entsprechend den Ergebnissen festlegen oder rollen. 1. Nennen Sie Conn.SetAutoCommit (False), um die Transaktion zu starten. 2. Führen Sie mehrere SQL -Operationen aus, z. B. einfügen und aktualisieren. 3. Rufen Sie Conn.Commit () an, wenn alle Vorg?nge erfolgreich sind, und rufen Sie Conn.Rollback () auf, wenn eine Ausnahme auftritt, um die Datenkonsistenz zu gew?hrleisten. Gleichzeitig sollten Try-with-Ressourcen verwendet werden, um Ressourcen zu verwalten, Ausnahmen ordnungsgem?? zu behandeln und Verbindungen zu schlie?en, um Verbindungsleckage zu vermeiden. Darüber hinaus wird empfohlen, Verbindungspools zu verwenden und Save -Punkte zu setzen, um teilweise Rollback zu erreichen und Transaktionen so kurz wie m?glich zu halten, um die Leistung zu verbessern.
 Vergleich von Java Frameworks: Spring Boot vs Quarkus gegen Micronaut
Aug 04, 2025 pm 12:48 PM
Vergleich von Java Frameworks: Spring Boot vs Quarkus gegen Micronaut
Aug 04, 2025 pm 12:48 PM
Pre-Formancetartuptimemoryusage, QuarkusandmicronautleadduToCompile-Time-foringandgraalvSupport, WithQuarkusofttenperformLightBetterin serverloser Szenarien.2. Thyvelopecosystem,
 Gehen Sie zum Beispiel für HTTP Middleware -Protokollierung
Aug 03, 2025 am 11:35 AM
Gehen Sie zum Beispiel für HTTP Middleware -Protokollierung
Aug 03, 2025 am 11:35 AM
HTTP-Protokoll Middleware in Go kann Anforderungsmethoden, Pfade, Client-IP und zeitaufw?ndiges Aufzeichnen aufzeichnen. 1. Verwenden Sie http.Handlerfunc, um den Prozessor zu wickeln, 2. Nehmen Sie die Startzeit und die Endzeit vor und nach dem Aufrufen als n?chstes auf. Der vollst?ndige Beispielcode wurde überprüft, um auszuführen und eignet sich zum Starten eines kleinen und mittelgro?en Projekts. Zu den Erweiterungsvorschl?gen geh?ren das Erfassen von Statuscodes, die Unterstützung von JSON -Protokollen und die Nachverfolgung von ID -IDs.
 Wie funktioniert die Müllsammlung in Java?
Aug 02, 2025 pm 01:55 PM
Wie funktioniert die Müllsammlung in Java?
Aug 02, 2025 pm 01:55 PM
Die Müllsammlung von Java (GC) ist ein Mechanismus, der automatisch den Speicher verwaltet, der das Risiko eines Speicherlecks verringert, indem unerreichbare Objekte zurückgeführt werden. 1.GC beurteilt die Zug?nglichkeit des Objekts aus dem Stammobjekt (z. B. Stapelvariablen, aktive Threads, statische Felder usw.) und nicht erreichbare Objekte als Müll markiert. 2. Basierend auf dem markierten Algorithmus markieren Sie alle erreichbaren Objekte und l?schen Sie nicht markierte Objekte. 3.. Verfolgen Sie eine Generationskollektionsstrategie: Die neue Generation (Eden, S0, S1) führt h?ufig MollGC aus; Die ?lteren Menschen erzielen weniger, dauert jedoch l?nger, um MajorGC durchzuführen. MetaPace speichert Klassenmetadaten. 4. JVM bietet eine Vielzahl von GC -Ger?ten: SerialGC ist für kleine Anwendungen geeignet; ParallelgC verbessert den Durchsatz; CMS reduziert sich
 Verwenden von HTML `Input` -Typen für Benutzerdaten
Aug 03, 2025 am 11:07 AM
Verwenden von HTML `Input` -Typen für Benutzerdaten
Aug 03, 2025 am 11:07 AM
Durch die Auswahl des richtigen HTMlinput -Typs kann die Datengenauigkeit verbessert, die Benutzererfahrung verbessert und die Benutzerfreundlichkeit verbessert werden. 1. W?hlen Sie die entsprechenden Eingabetypen gem?? dem Datentyp aus, z. B. Text, E -Mail, Tel, Nummer und Datum, die automatisch überprüft und an die Tastatur anpassen k?nnen. 2. Verwenden Sie HTML5, um neue Typen wie URL, Farbe, Reichweite und Suche hinzuzufügen, die eine intuitivere Interaktionsmethode bieten k?nnen. 3.. Verwenden Sie Platzhalter und erforderliche Attribute, um die Effizienz und Genauigkeit der Formulierung zu verbessern. Es sollte jedoch beachtet werden, dass der Platzhalter das Etikett nicht ersetzen kann.
 Vergleich von Java -Build -Werkzeugen: Maven vs. Gradle
Aug 03, 2025 pm 01:36 PM
Vergleich von Java -Build -Werkzeugen: Maven vs. Gradle
Aug 03, 2025 pm 01:36 PM
GradleStheBetterChoiceFormostnewProjectsDuetoitSuperiorFlexibilit?t, Leistung und ModerntoolingSupport.1.GRADLE'SGROOVY/KOTLINDSLISMORECONCISEANDEIPRESSIVETHANMANMANBOSEXML.2.GRAGRECONCISEANDEPRPRESSIVETHANMAVENSVOSEXML.2.
 Wie benutze ich das Beobachtermuster in Java?
Aug 02, 2025 am 11:52 AM
Wie benutze ich das Beobachtermuster in Java?
Aug 02, 2025 am 11:52 AM
Die klare Antwort auf diese Frage ist die Empfehlung, das Beobachtermuster mithilfe einer benutzerdefinierten Observer -Schnittstelle zu implementieren. 1. Obwohl Java beobachtbar und Beobachter liefert, ist erstere eine Klasse und wurde veraltet und fehlt Flexibilit?t. 2. Die moderne empfohlene Praxis besteht darin, eine funktionale Observer -Schnittstelle zu definieren, und das Subjekt beh?lt die Beobachterliste bei und benachrichtigt alle Beobachter, wenn sich der Zustand ?ndert. 3.. Es kann in Kombination mit Lambda -Ausdrücken verwendet werden, um die Einfachheit und Wartbarkeit des Codes zu verbessern. V. Daher sollten neue Projekte ein benutzerdefiniertes Observer-Schnittstellenschema annehmen, das Typen ist, einfach zu testen und sich auf moderne Java spezialisiert zu haben
 Java Concurrency Utilities: ExecutorService und Gabel/Join
Aug 03, 2025 am 01:54 AM
Java Concurrency Utilities: ExecutorService und Gabel/Join
Aug 03, 2025 am 01:54 AM
Der ExecutorService eignet sich zur asynchronen Ausführung unabh?ngiger Aufgaben wie E/A -Operationen oder Zeitaufgaben, verwendete den Thread -Pool zur Verwaltung von Parallelit?t, sendete Runnable- oder Callable -Aufgaben über Senden und erzielte Ergebnisse mit Zukunft. Achten Sie auf das Risiko unbegrenzter Warteschlangen und schlie?en Sie den Fadenpool ausdrücklich; 2. Das Fork/Join-Framework ist für CPU-intensive Aufgaben von Split-Gouvernance-Aufgaben ausgelegt, basierend auf der Verteilung und kontroversen Methoden und Work-Stellungsalgorithmen und realisiert rekursive Aufteilung von Aufgaben durch Recursivetask oder Recursiveaction, die durch Forkjoinpool geplant und ausgeführt wird. Es eignet sich für gro?e Array -Summierungs- und Sortierszenarien. Der Split -Schwellenwert sollte vernünftigerweise eingestellt werden, um Overhead zu vermeiden. 3.. Auswahlbasis: unabh?ngig
