
 Technologie-Peripherieger?te
KI
NeRFs Durchbruch bei der BEV-Generalisierungsleistung: Der erste dom?nenübergreifende Open-Source-Code implementiert Sim2Real erfolgreich
Technologie-Peripherieger?te
KI
NeRFs Durchbruch bei der BEV-Generalisierungsleistung: Der erste dom?nenübergreifende Open-Source-Code implementiert Sim2Real erfolgreich
NeRFs Durchbruch bei der BEV-Generalisierungsleistung: Der erste dom?nenübergreifende Open-Source-Code implementiert Sim2Real erfolgreich
Jan 11, 2024 am 10:24 AM
Oben geschrieben und die pers?nliche Zusammenfassung des Autors
Die Erkennung aus der Vogelperspektive (BEV) ist eine Erkennungsmethode, die mehrere Surround-View-Kameras zusammenführt. Die meisten aktuellen Algorithmen werden anhand desselben Datensatzes trainiert und ausgewertet, was dazu führt, dass diese Algorithmen an die unver?nderten internen Parameter der Kamera (Kameratyp) und externen Parameter (Kameraplatzierung) überpassen. In diesem Artikel wird ein BEV-Erkennungsframework vorgeschlagen, das auf implizitem Rendering basiert und das Problem der Objekterkennung in unbekannten Dom?nen l?sen kann. Das Framework verwendet implizites Rendering, um die Beziehung zwischen der 3D-Position des Objekts und der perspektivischen Position einer einzelnen Ansicht herzustellen, die zur Korrektur der perspektivischen Verzerrung verwendet werden kann. Mit dieser Methode werden erhebliche Leistungsverbesserungen bei der Dom?nengeneralisierung (DG) und der unüberwachten Dom?nenanpassung (UDA) erzielt. Diese Methode ist der erste Versuch, ausschlie?lich virtuelle Datens?tze für das Training und die Bewertung der BEV-Erkennung in realen Szenarien zu verwenden, wodurch die Grenzen zwischen virtuell und real durchbrochen werden k?nnen, um Tests im geschlossenen Regelkreis durchzuführen.
- Papier-Link: https://arxiv.org/pdf/2310.11346.pdf
- Code-Link: https://github.com/EnVision-Research/Generalizable-BEV

BEV-Erkennungsdom?ne allgemein Problemhintergrund
Multikameraerkennung bezieht sich auf die Aufgabe, mithilfe mehrerer Kameras Objekte im dreidimensionalen Raum zu erkennen und zu lokalisieren. Durch die Kombination von Informationen aus verschiedenen Blickwinkeln kann die 3D-Objekterkennung mit mehreren Kameras genauere und robustere Objekterkennungsergebnisse liefern, insbesondere in Situationen, in denen Ziele aus bestimmten Blickwinkeln m?glicherweise verdeckt oder teilweise sichtbar sind. In den letzten Jahren hat die Bird-Eye-View-Methode (BEV) gro?e Aufmerksamkeit bei Erkennungsaufgaben mit mehreren Kameras erhalten. Obwohl diese Methoden bei der Informationsfusion mit mehreren Kameras Vorteile bieten, kann die Leistung dieser Methoden erheblich beeintr?chtigt werden, wenn sich die Testumgebung erheblich von der Trainingsumgebung unterscheidet.
Derzeit werden die meisten BEV-Erkennungsalgorithmen anhand desselben Datensatzes trainiert und ausgewertet, was dazu führt, dass diese Algorithmen zu empfindlich auf ?nderungen interner und externer Kameraparameter und st?dtischer Stra?enbedingungen reagieren, was zu schwerwiegenden überanpassungsproblemen führt. In praktischen Anwendungen müssen BEV-Erkennungsalgorithmen jedoch h?ufig an verschiedene neue Modelle und neue Kameras angepasst werden, was zum Versagen dieser Algorithmen führt. Daher ist es wichtig, die Generalisierbarkeit der BEV-Erkennung zu untersuchen. Darüber hinaus ist die Closed-Loop-Simulation auch für das autonome Fahren sehr wichtig, kann jedoch derzeit nur in virtuellen Motoren wie Carla ausgewertet werden. Daher ist es notwendig, das Problem der Dom?nenunterschiede zwischen virtuellen Engines und realen Szenen zu l?sen. Dom?nengeneralisierung (DG) und unbeaufsichtigte Dom?nenanpassung (UDA) sind zwei vielversprechende Methoden, um Verteilungsrichtungsverschiebungen zu mildern. DG-Methoden entkoppeln und eliminieren h?ufig dom?nenspezifische Merkmale und verbessern so die Generalisierungsleistung in unsichtbaren Dom?nen. Für UDA mildern neuere Methoden die Dom?nenverschiebung durch die Generierung von Pseudobezeichnungen oder die Ausrichtung latenter Merkmalsverteilungen. Allerdings ist das Erlernen von aussichts- und umgebungsunabh?ngigen Funktionen für die reine visuelle Wahrnehmung ohne die Verwendung von Daten aus verschiedenen Blickwinkeln, Kameraparametern und Umgebungen eine gro?e Herausforderung.
Beobachtungen zeigen, dass die 2D-Erkennung aus einer einzigen Perspektive (Kameraebene) tendenziell st?rkere Generalisierungsf?higkeiten aufweist als die 3D-Objekterkennung aus mehreren Perspektiven, wie in der Abbildung dargestellt. Einige Studien haben die Integration der 2D-Erkennung in die BEV-Erkennung untersucht, beispielsweise die Fusion von 2D-Informationen in 3D-Detektoren oder die Herstellung einer 2D-3D-Konsistenz. Die 2D-Informationsfusion ist eher eine lernbasierte Methode als eine Mechanismusmodellierungsmethode und wird immer noch stark von der Dom?nenmigration beeintr?chtigt. Bestehende 2D-3D-Konsistenzmethoden projizieren die 3D-Ergebnisse auf eine zweidimensionale Ebene und stellen Konsistenz her. Diese Einschr?nkung kann die semantischen Informationen in der Zieldom?ne sch?digen, anstatt die geometrischen Informationen der Zieldom?ne zu ?ndern. Darüber hinaus macht dieser 2D-3D-Konsistenzansatz einen einheitlichen Ansatz für alle Erkennungsk?pfe zu einer Herausforderung.
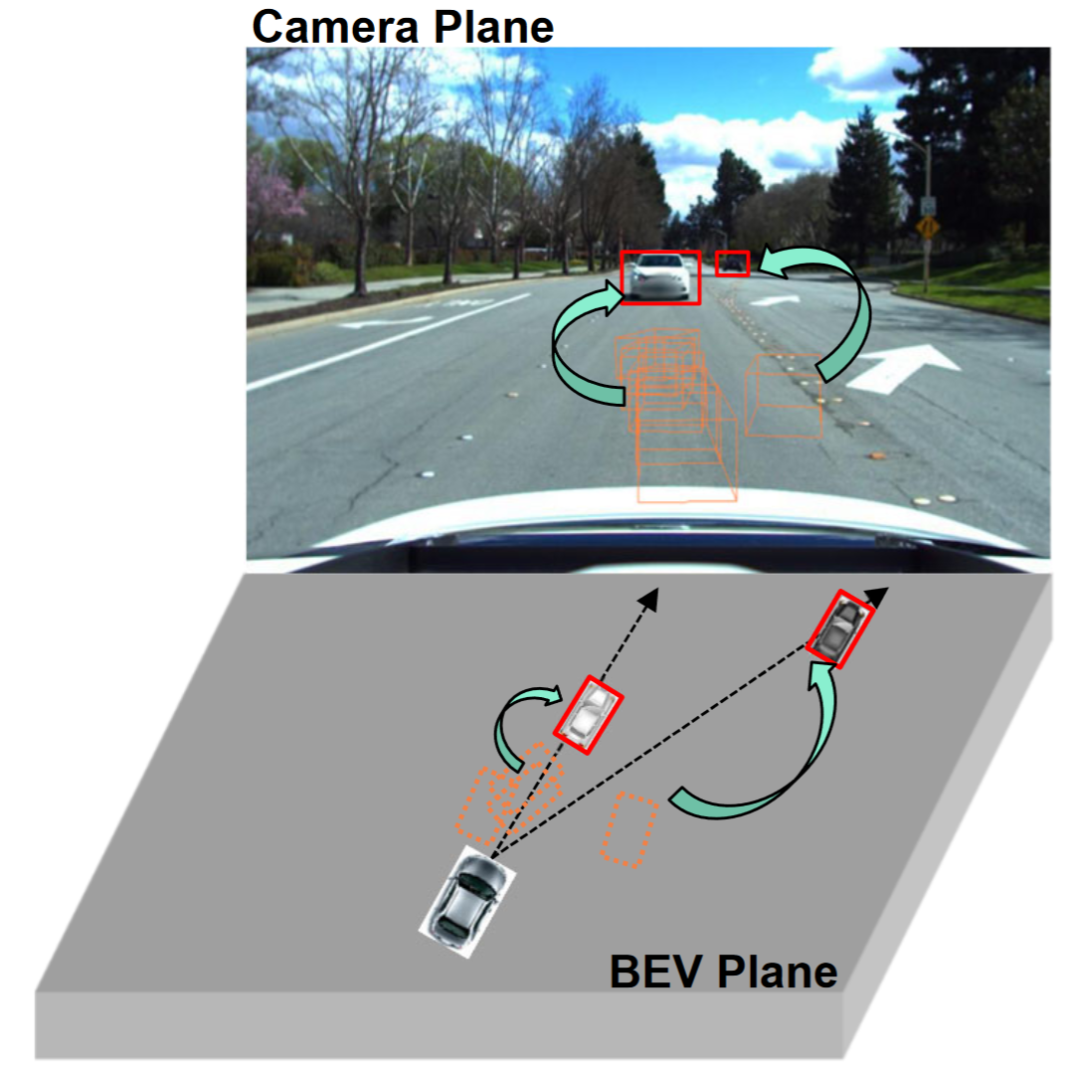
Dieser Artikel schl?gt ein verallgemeinertes BEV-Erkennungsframework vor, das auf Perspektivdebiasing basiert. Dieses Framework kann dem Modell nicht nur dabei helfen, Perspektiven und kontextinvariante Merkmale in der Quelldom?ne zu lernen. Zweidimensionale Detektoren k?nnen auch verwendet werden, um falsche geometrische Merkmale im Zielbereich weiter zu korrigieren.
- Dieses Papier ist der erste Versuch, die unbeaufsichtigte Dom?nenanpassung bei der BEV-Erkennung zu untersuchen und einen Benchmark festzulegen. Sowohl mit UDA- als auch mit DG-Protokollen werden hochmoderne Ergebnisse erzielt.
- In diesem Artikel wird erstmals das Training an einem virtuellen Motor ohne reale Szenenanmerkungen untersucht, um reale BEV-Erkennungsaufgaben zu erfüllen.
Problemdefinition
Die Forschung konzentriert sich haupts?chlich auf die Verbesserung der Generalisierung der BEV-Erkennung. Um dieses Ziel zu erreichen, untersucht dieses Papier zwei Protokolle mit weit verbreiteter praktischer Anwendung, n?mlich Dom?nengeneralisierung (DG) und unüberwachte Dom?nenanpassung (UDA):
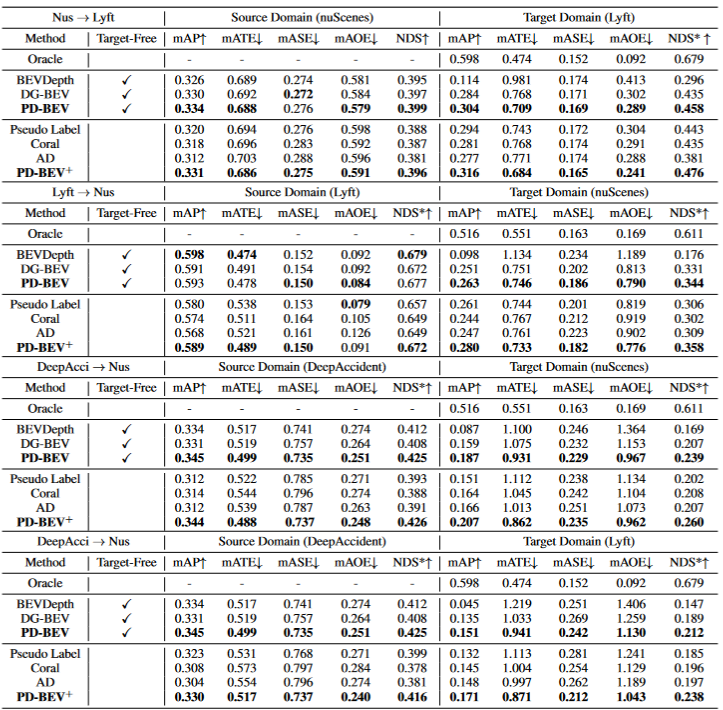
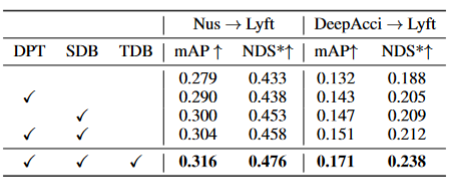
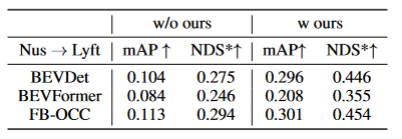
Durch BEV-Generalisierung (DG) erkannte Dom?nen:Trainieren Sie einen BEV-Erkennungsalgorithmus in einem vorhandenen Datensatz (Quelldom?ne), um die Erkennungsleistung in einem unbekannten Datensatz (Zieldom?ne) zu verbessern. Beispielsweise kann das Training eines BEV-Erkennungsmodells in einem bestimmten Fahrzeug oder Szenario direkt auf eine Vielzahl unterschiedlicher Fahrzeuge und Szenarien übertragen werden. Unüberwachte Dom?nenanpassung (UDA) für die BEV-Erkennung: Trainieren Sie einen BEV-Erkennungsalgorithmus anhand eines vorhandenen Datensatzes (Quelldom?ne) und verwenden Sie unbeschriftete Daten in der Zieldom?ne, um die Erkennungsleistung zu verbessern. Beispielsweise kann in einem neuen Fahrzeug oder in einer neuen Stadt allein das Sammeln einiger unbeaufsichtigter Daten die Leistung des Modells im neuen Fahrzeug und in der neuen Umgebung verbessern. Es ist erw?hnenswert, dass der einzige Unterschied zwischen DG und UDA darin besteht, ob unbeschriftete Daten der Zieldom?ne verwendet werden k?nnen. Um das unbekannte L=[x,y,z] des Objekts zu erkennen, bestehen die meisten BEV-Erkennungen aus zwei Schlüsselteilen: (1) Erhalten Sie Bildmerkmale aus verschiedenen Betrachtungswinkeln; 2) Fusion dieser Bilder. Merkmale werden in den BEV-Raum übertragen und das endgültige Vorhersageergebnis wird erhalten: Die obige Formel beschreibt, dass die Dom?nenabweichung aus der Phase der Merkmalsextraktion oder der Phase der BEV-Fusion stammen kann. Dann wurde dieser Artikel im Anhang vorangetrieben und die Betrachtungswinkelabweichung des endgültigen 3D-Vorhersageergebnisses projiziert auf das 2D-Ergebnis wie folgt erhalten: wobei k_u, b_u, k_v und b_v mit dem Dom?nenoffset des BEV-Encoders zusammenh?ngen, d (u, v) ist die endgültige vorhergesagte Tiefeninformation des Modells. c_u und c_v stellen die Koordinaten des optischen Zentrums der Kamera auf der UV-Bildebene dar. Die obige Gleichung liefert mehrere wichtige Folgerungen: (1) Das Vorhandensein eines endgültigen Positionsversatzes führt zu einer perspektivischen Verzerrung, was zeigt, dass die Optimierung der perspektivischen Verzerrung dazu beitragen kann, den Dom?nenversatz zu verringern. (2) Sogar die Position des Punktes auf dem optischen Mittelstrahl der Kamera in der Einzelansicht-Bildebene verschiebt sich. Intuitiv ?ndert die Dom?nenverschiebung die Position von BEV-Features, was auf eine überanpassung aufgrund begrenzter Trainingsdaten-Ansichtspunkte und Kameraparameter zurückzuführen ist. Um dieses Problem zu l?sen, ist es wichtig, neue Ansichtsbilder von BEV-Funktionen erneut zu rendern, damit das Netzwerk ansichts- und umgebungsunabh?ngige Funktionen lernen kann. Vor diesem Hintergrund zielt diese Forschung darauf ab, die perspektivische Abweichung im Zusammenhang mit verschiedenen Rendering-Standpunkten zu l?sen, um die Generalisierungsf?higkeit des Modells zu verbessern. Detaillierte Erl?uterung des PD-BEV-Algorithmus. PD-BEV ist in drei Teile unterteilt: Semantik Rendering, Quelldom?nenentfernungs-Bias und Zieldom?nen-Debiasing sind in Abbildung 1 dargestellt. Semantisches Rendering erl?utert, wie durch BEV-Funktionen die perspektivische Beziehung zwischen 2D und 3D hergestellt wird. Beim Debiasing der Quelldom?ne wird beschrieben, wie die F?higkeiten zur Modellgeneralisierung durch semantisches Rendering in der Quelldom?ne verbessert werden k?nnen. Zieldom?nen-Debiasing beschreibt die Verwendung unbeschrifteter Daten in der Zieldom?ne, um die F?higkeiten zur Modellgeneralisierung durch semantisches Rendering zu verbessern. Semantisches Rendering Um die Generalisierungsleistung des Modells zu verbessern, müssen in der Quelldom?ne mehrere wichtige Punkte verbessert werden. Erstens k?nnen die Heatmap und die Eigenschaften der neuen gerenderten Ansicht mithilfe der 3D-Box der Quelldom?ne überwacht werden, um perspektivische Verzerrungen zu reduzieren. Zweitens k?nnen normalisierte Tiefeninformationen verwendet werden, um Bildkodierern dabei zu helfen, geometrische Informationen besser zu lernen. Diese Verbesserungen werden dazu beitragen, die Generalisierungsleistung des Modells zu verbessern. Durch diesen Vorgang kann die überanpassung interner und externer Parameter der Kamera reduziert und die Robustheit gegenüber neuen Perspektiven verbessert werden. Es ist erw?hnenswert, dass in diesem Artikel das überwachte Lernen von RGB-Bildern in W?rmekarten von Objektzentren umgewandelt wird, um die M?ngel des Mangels an neuer perspektivischer RGB-überwachung im Bereich des unbemannten Fahrens zu vermeiden. Geometrische überwachung: Die Bereitstellung expliziter Tiefeninformationen kann effektiv sein Verbessern Sie die Leistung der 3D-Objekterkennung mit mehreren Kameras. Die Tiefe der Netzwerkvorhersagen tendiert jedoch dazu, die intrinsischen Parameter zu stark anzupassen. Daher basiert dieser Artikel auf einem virtuellen Tiefenansatz: wobei BCE() den bin?ren Kreuzentropieverlust darstellt und D_{pre} die vorhergesagte Tiefe von DepthNet darstellt. f_u und f_v sind die u- bzw. v-Brennweiten der Bildebene, und U ist eine Konstante. Es ist erw?hnenswert, dass es sich bei der Tiefe hier um die Tiefeninformationen im Vordergrund handelt, die durch die Verwendung von 3D-Boxen anstelle von Punktwolken bereitgestellt werden. Auf diese Weise konzentriert sich DepthNet eher auf die Tiefe von Vordergrundobjekten. Schlie?lich wird die virtuelle Tiefe wieder in die tats?chliche Tiefe umgewandelt, wenn die semantischen Merkmale mithilfe der tats?chlichen Tiefeninformationen auf die BEV-Ebene angehoben werden. Debiasing der Zieldom?ne In der Zieldom?ne gibt es keine Beschriftung, daher kann die 3D-Box-überwachung nicht zur Verbesserung der Generalisierungsf?higkeit des Modells verwendet werden. In diesem Artikel wird daher erl?utert, dass 2D-Erkennungsergebnisse robuster sind als 3D-Ergebnisse. Daher verwendet dieser Artikel vorab trainierte 2D-Detektoren im Quellbereich zur überwachung der gerenderten Perspektive und verwendet au?erdem den Pseudo-Label-Mechanismus: Dieser Vorgang kann die genaue 2D-Erkennung effektiv nutzen, um die Vordergrundzielposition im BEV-Raum zu korrigieren, was eine unbeaufsichtigte Regularisierung der Zieldom?ne darstellt. Um die Korrekturf?higkeit der 2D-Vorhersage weiter zu verbessern, wird eine Pseudomethode verwendet, um die Zuverl?ssigkeit der vorhergesagten W?rmekarte zu erh?hen. Dieses Papier liefert mathematische Beweise in 3.2 und erg?nzende Materialien, um die Ursache von 2D-Projektionsfehlern in 3D-Ergebnissen zu erkl?ren. Es wird auch erkl?rt, warum Voreingenommenheit auf diese Weise beseitigt werden kann. Einzelheiten finden Sie im Originalpapier. Obwohl in diesem Artikel einige Netzwerke hinzugefügt wurden, um das Training zu erleichtern, sind diese Netzwerke w?hrend der Inferenz nicht erforderlich. Mit anderen Worten, unsere Methode ist auf Situationen anwendbar, in denen die meisten BEV-Erkennungsmethoden perspektivinvariante Merkmale lernen. Um die Wirksamkeit unseres Frameworks zu testen, verwenden wir BEVDepth zur Bewertung. Der ursprüngliche Verlust von BEVDepth wird in der Quelldom?ne als Hauptüberwachung für die 3D-Erkennung verwendet. Zusammenfassend ist der endgültige Verlust des Algorithmus: Tabelle 1 zeigt den Vergleich der Auswirkungen verschiedener Methoden unter den Protokollen Dom?nengeneralisierung (DG) und unbeaufsichtigte Dom?nenanpassung (UDA). Unter diesen repr?sentiert Target-Free das DG-Protokoll, und Pseudo Label, Coral und AD sind einige g?ngige UDA-Methoden. Wie aus der Grafik ersichtlich ist, erzielen diese Methoden allesamt deutliche Verbesserungen im Zielbereich. Dies legt nahe, dass semantisches Rendering als Brücke dient, um das Erlernen perspektivinvarianter Merkmale gegenüber Dom?nenverschiebungen zu unterstützen. Darüber hinaus beeintr?chtigen diese Methoden nicht die Leistung der Quelldom?ne und bieten in den meisten F?llen sogar einige Verbesserungen. Es sollte insbesondere erw?hnt werden, dass DeepAccident auf der Grundlage der virtuellen Carla-Engine entwickelt wurde. Nach dem Training mit DeepAccident hat der Algorithmus zufriedenstellende Generalisierungsf?higkeiten erreicht. Darüber hinaus wurden andere BEV-Erkennungsmethoden getestet, deren Generalisierungsleistung jedoch ohne spezielles Design sehr schlecht ist. Um die F?higkeit zur Nutzung unbeaufsichtigter Datens?tze in der Zieldom?ne weiter zu überprüfen, wurde au?erdem ein UDA-Benchmark erstellt und UDA-Methoden (einschlie?lich Pseudo Label, Coral und AD) auf DG-BEV angewendet. Experimente zeigen, dass diese Methoden erhebliche Leistungsverbesserungen mit sich bringen. Beim impliziten Rendering werden 2D-Detektoren mit besserer Generalisierungsleistung voll ausgenutzt, um die falschen geometrischen Informationen von 3D-Detektoren zu korrigieren. Darüber hinaus wurde festgestellt, dass die meisten Algorithmen dazu neigen, die Leistung der Quelldom?ne zu beeintr?chtigen, w?hrend unsere Methode relativ mild ist. Es ist erw?hnenswert, dass AD und Coral beim übergang von virtuellen zu realen Datens?tzen deutliche Verbesserungen zeigen, in realen Tests jedoch Leistungseinbu?en zeigen. Dies liegt daran, dass diese beiden Algorithmen für die Verarbeitung von Stil?nderungen konzipiert sind, in Szenen mit kleinen Stil?nderungen jedoch m?glicherweise semantische Informationen zerst?ren. Der Pseudo-Label-Algorithmus kann die Generalisierungsleistung des Modells verbessern, indem er das Vertrauen in einige relativ gute Zieldom?nen erh?ht. Eine blinde Erh?hung des Vertrauens in die Zieldom?ne führt jedoch tats?chlich zu einer Verschlechterung des Modells. Die experimentellen Ergebnisse beweisen, dass dieser Algorithmus eine signifikante Leistungsverbesserung in DG und UDA erzielt hat. Die experimentellen Ergebnisse der Ablation für drei Schlüsselkomponenten sind in Tabelle 2 dargestellt: 2D-Detektor-Pre-Training (DPT), Source Domain Removal Biasing (SDB) und Target Domain Debiasing (TDB). Die experimentellen Ergebnisse zeigen, dass jede Komponente verbessert wurde, wobei SDB und TDB relativ signifikante Auswirkungen zeigen Tabelle 3 zeigt, dass der Algorithmus auf die Algorithmen BEVFormer und FB-OCC migriert werden kann. Da dieser Algorithmus nur zus?tzliche Operationen an Bildfunktionen und BEV-Funktionen erfordert, kann er Algorithmen mit BEV-Funktionen verbessern. Abbildung 5 zeigt die erkannten unbeschrifteten Objekte. Die erste Zeile ist das 3D-Feld des Etiketts und die zweite Zeile ist das Erkennungsergebnis des Algorithmus. Blaue K?stchen zeigen an, dass der Algorithmus einige unbeschriftete K?stchen erkennen kann. Dies zeigt, dass die Methode sogar unbeschriftete Proben im Zielbereich erkennen kann, beispielsweise zu weit entfernte Fahrzeuge oder in Geb?uden auf beiden Stra?enseiten. In diesem Artikel wird ein universelles 3D-Objekterkennungsframework mit mehreren Kameras vorgeschlagen, das auf perspektivischer Depolarisation basiert und das Objekterkennungsproblem in unbekannten Feldern l?sen kann. Das Framework erreicht eine konsistente und genaue Erkennung, indem es 3D-Erkennungsergebnisse auf eine 2D-Kameraebene projiziert und perspektivische Verzerrungen korrigiert. Darüber hinaus führt das Framework auch eine Strategie zur Perspektivdebiasierung ein, um die Robustheit des Modells durch die Darstellung von Bildern aus verschiedenen Perspektiven zu verbessern. Experimentelle Ergebnisse zeigen, dass diese Methode erhebliche Leistungsverbesserungen bei der Dom?nengeneralisierung und der unbeaufsichtigten Dom?nenanpassung erzielt. Darüber hinaus kann diese Methode auch an virtuellen Datens?tzen trainiert werden, ohne dass eine Anmerkung zu realen Szenen erforderlich ist, was Komfort für Echtzeitanwendungen und den Einsatz in gro?em Ma?stab bietet. Diese Highlights veranschaulichen die Herausforderungen und das Potenzial der Methode bei der L?sung der 3D-Objekterkennung mit mehreren Kameras. In diesem Artikel wird versucht, die Ideen von Nerf zu nutzen, um die Generalisierungsf?higkeit von BEV zu verbessern, und es k?nnen auch gekennzeichnete Quelldom?nendaten und unbeschriftete Zieldom?nendaten verwendet werden. Darüber hinaus wurde das experimentelle Paradigma von Sim2Real ausprobiert, das potenziellen Wert für das autonome Fahren im geschlossenen Regelkreis hat. Sowohl qualitativ als auch quantitativ gibt es gute Ergebnisse, und der Open-Source-Code ist einen Blick wert Originallink: https://mp.weixin.qq.com/s/GRLu_JW6qZ_nQ9sLiE0p2gBetrachtungswinkelabweichungsdefinition
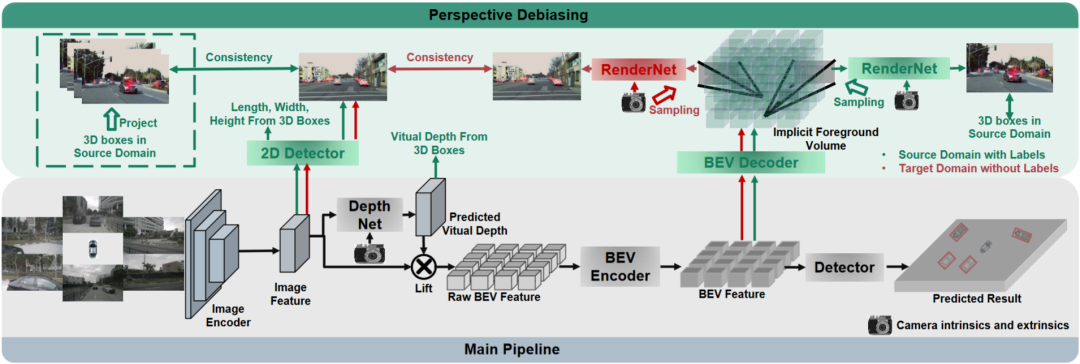 Da viele Algorithmen das BEV-Volumen in zweidimensionale Merkmale komprimieren, verwenden wir zun?chst den BEV-Decoder, um die BEV-Merkmale in ein Volumen umzuwandeln:
Da viele Algorithmen das BEV-Volumen in zweidimensionale Merkmale komprimieren, verwenden wir zun?chst den BEV-Decoder, um die BEV-Merkmale in ein Volumen umzuwandeln: Die obige Formel ist eigentlich die BEV-Ebene Zur Verbesserung wurde eine H?henbema?ung hinzugefügt. Dann k?nnen die internen und externen Parameter der Kamera in diesem Volumen abgetastet werden, um eine 2D-Feature-Map zu erstellen, und dann werden die 2D-Feature-Map und die internen und externen Parameter der Kamera an ein RenderNet gesendet, um die Heatmap und die Objekteigenschaften vorherzusagen die entsprechende Perspektive. Durch solche Operationen ?hnlich wie bei Nerf kann eine Brücke zwischen 2D und 3D geschlagen werden.
Debiasing der Quelldom?ne
Perspektivische semantische überwachung: Basierend auf semantischem Rendering werden Heatmaps und Attribute aus verschiedenen Perspektiven gerendert (Ausgabe von RenderNet). Gleichzeitig werden die internen und externen Parameter einer Kamera zuf?llig abgetastet und der Objektkasten anhand dieser internen und externen Parameter aus den 3D-Koordinaten in die zweidimensionale Kameraebene projiziert. Verwenden Sie dann Fokusverlust und L1-Verlust, um die projizierte 2D-Box und die Renderergebnisse einzuschr?nken:
Gesamtaufsicht
Dom?nenübergreifende experimentelle Ergebnisse
Zusammenfassung

Das obige ist der detaillierte Inhalt vonNeRFs Durchbruch bei der BEV-Generalisierungsleistung: Der erste dom?nenübergreifende Open-Source-Code implementiert Sim2Real erfolgreich. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Hei?e KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem v?llig kostenlosen KI-Gesichtstausch-Tool aus!

Hei?er Artikel
Hei?e Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Das neueste Meisterwerk des MIT: Verwendung von GPT-3.5 zur L?sung des Problems der Erkennung von Zeitreihenanomalien
Jun 08, 2024 pm 06:09 PM
Das neueste Meisterwerk des MIT: Verwendung von GPT-3.5 zur L?sung des Problems der Erkennung von Zeitreihenanomalien
Jun 08, 2024 pm 06:09 PM
Heute m?chte ich Ihnen einen letzte Woche vom MIT ver?ffentlichten Artikel vorstellen, in dem GPT-3.5-turbo verwendet wird, um das Problem der Erkennung von Zeitreihenanomalien zu l?sen, und zun?chst die Wirksamkeit von LLM bei der Erkennung von Zeitreihenanomalien überprüft wird. Im gesamten Prozess gibt es keine Feinabstimmung, und GPT-3.5-Turbo wird direkt zur Anomalieerkennung verwendet. Der Kern dieses Artikels besteht darin, wie man Zeitreihen in Eingaben umwandelt, die von GPT-3.5-Turbo erkannt werden k?nnen, und wie man sie entwirft Eingabeaufforderungen oder Pipelines, damit LLM die Anomalieerkennungsaufgabe l?sen kann. Lassen Sie mich Ihnen diese Arbeit im Detail vorstellen. Titel des Bildpapiers: Largelingualmodelscanbezero-shotanomalydete
 So bewerten Sie die Kosteneffizienz der kommerziellen Unterstützung für Java-Frameworks
Jun 05, 2024 pm 05:25 PM
So bewerten Sie die Kosteneffizienz der kommerziellen Unterstützung für Java-Frameworks
Jun 05, 2024 pm 05:25 PM
Die Bewertung des Kosten-/Leistungsverh?ltnisses des kommerziellen Supports für ein Java-Framework umfasst die folgenden Schritte: Bestimmen Sie das erforderliche Ma? an Sicherheit und Service-Level-Agreement-Garantien (SLA). Die Erfahrung und das Fachwissen des Forschungsunterstützungsteams. Erw?gen Sie zus?tzliche Services wie Upgrades, Fehlerbehebung und Leistungsoptimierung. W?gen Sie die Kosten für die Gesch?ftsunterstützung gegen Risikominderung und Effizienzsteigerung ab.
 Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochaufl?senden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochaufl?senden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
01Ausblicksübersicht Derzeit ist es schwierig, ein angemessenes Gleichgewicht zwischen Detektionseffizienz und Detektionsergebnissen zu erreichen. Wir haben einen verbesserten YOLOv5-Algorithmus zur Zielerkennung in hochaufl?senden optischen Fernerkundungsbildern entwickelt, der mehrschichtige Merkmalspyramiden, Multierkennungskopfstrategien und hybride Aufmerksamkeitsmodule verwendet, um die Wirkung des Zielerkennungsnetzwerks in optischen Fernerkundungsbildern zu verbessern. Laut SIMD-Datensatz ist der mAP des neuen Algorithmus 2,2 % besser als YOLOv5 und 8,48 % besser als YOLOX, wodurch ein besseres Gleichgewicht zwischen Erkennungsergebnissen und Geschwindigkeit erreicht wird. 02 Hintergrund und Motivation Mit der rasanten Entwicklung der Fernerkundungstechnologie wurden hochaufl?sende optische Fernerkundungsbilder verwendet, um viele Objekte auf der Erdoberfl?che zu beschreiben, darunter Flugzeuge, Autos, Geb?ude usw. Objekterkennung bei der Interpretation von Fernerkundungsbildern
 Wie ist die Lernkurve von PHP-Frameworks im Vergleich zu anderen Sprach-Frameworks?
Jun 06, 2024 pm 12:41 PM
Wie ist die Lernkurve von PHP-Frameworks im Vergleich zu anderen Sprach-Frameworks?
Jun 06, 2024 pm 12:41 PM
Die Lernkurve eines PHP-Frameworks h?ngt von Sprachkenntnissen, Framework-Komplexit?t, Dokumentationsqualit?t und Community-Unterstützung ab. Die Lernkurve von PHP-Frameworks ist im Vergleich zu Python-Frameworks h?her und im Vergleich zu Ruby-Frameworks niedriger. Im Vergleich zu Java-Frameworks haben PHP-Frameworks eine moderate Lernkurve, aber eine kürzere Einstiegszeit.
 Wie wirken sich die Lightweight-Optionen von PHP-Frameworks auf die Anwendungsleistung aus?
Jun 06, 2024 am 10:53 AM
Wie wirken sich die Lightweight-Optionen von PHP-Frameworks auf die Anwendungsleistung aus?
Jun 06, 2024 am 10:53 AM
Das leichte PHP-Framework verbessert die Anwendungsleistung durch geringe Gr??e und geringen Ressourcenverbrauch. Zu seinen Merkmalen geh?ren: geringe Gr??e, schneller Start, geringer Speicherverbrauch, verbesserte Reaktionsgeschwindigkeit und Durchsatz sowie reduzierter Ressourcenverbrauch. Praktischer Fall: SlimFramework erstellt eine REST-API, nur 500 KB, hohe Reaktionsf?higkeit und hoher Durchsatz
 Die RedMagic Tablet 3D Explorer Edition bietet eine brillenlose 3D-Anzeige
Sep 06, 2024 am 06:45 AM
Die RedMagic Tablet 3D Explorer Edition bietet eine brillenlose 3D-Anzeige
Sep 06, 2024 am 06:45 AM
Die RedMagic Tablet 3D Explorer Edition wurde zusammen mit dem Gaming Tablet Pro auf den Markt gebracht. W?hrend sich Letzteres jedoch eher an Gamer richtet, ist Ersteres eher auf Unterhaltung ausgerichtet. Das neue Android-Tablet verfügt über das, was das Unternehmen als ?3D-Funktion mit blo?em Auge“ bezeichnet
 Roadmap zum Java Framework-Lernen: Best Practices in verschiedenen Bereichen
Jun 05, 2024 pm 08:53 PM
Roadmap zum Java Framework-Lernen: Best Practices in verschiedenen Bereichen
Jun 05, 2024 pm 08:53 PM
Roadmap zum Java-Framework-Lernen für verschiedene Bereiche: Webentwicklung: SpringBoot und PlayFramework. Persistenzschicht: Ruhezustand und JPA. Serverseitige reaktive Programmierung: ReactorCore und SpringWebFlux. Echtzeit-Computing: ApacheStorm und ApacheSpark. Cloud Computing: AWS SDK für Java und Google Cloud Java.
 Best Practices für die Dokumentation des Golang-Frameworks
Jun 04, 2024 pm 05:00 PM
Best Practices für die Dokumentation des Golang-Frameworks
Jun 04, 2024 pm 05:00 PM
Das Verfassen einer klaren und umfassenden Dokumentation ist für das Golang-Framework von entscheidender Bedeutung. Zu den Best Practices geh?rt die Befolgung eines etablierten Dokumentationsstils, beispielsweise des Go Coding Style Guide von Google. Verwenden Sie eine klare Organisationsstruktur, einschlie?lich überschriften, Unterüberschriften und Listen, und sorgen Sie für eine Navigation. Bietet umfassende und genaue Informationen, einschlie?lich Leitf?den für den Einstieg, API-Referenzen und Konzepte. Verwenden Sie Codebeispiele, um Konzepte und Verwendung zu veranschaulichen. Halten Sie die Dokumentation auf dem neuesten Stand, verfolgen Sie ?nderungen und dokumentieren Sie neue Funktionen. Stellen Sie Support und Community-Ressourcen wie GitHub-Probleme und Foren bereit. Erstellen Sie praktische Beispiele, beispielsweise eine API-Dokumentation.
