
 Technology peripherals
AI
Understanding the Evolution of ChatGPT: Part 3- Insights from Codex and InstructGPT
Technology peripherals
AI
Understanding the Evolution of ChatGPT: Part 3- Insights from Codex and InstructGPT
Understanding the Evolution of ChatGPT: Part 3- Insights from Codex and InstructGPT
Feb 26, 2025 am 02:58 AM
This article delves into the practical aspects of fine-tuning large language models (LLMs), focusing on Codex and InstructGPT as prime examples. It's the third in a series exploring GPT models, building upon previous discussions of pre-training and scaling.

Fine-tuning is crucial because while pre-trained LLMs are versatile, they often fall short of specialized models tailored to specific tasks. Furthermore, even powerful models like GPT-3 may struggle with complex instructions and maintaining safety and ethical standards. This necessitates fine-tuning strategies.
The article highlights two key fine-tuning challenges: adapting to new modalities (like Codex's adaptation to code generation) and aligning the model with human preferences (as demonstrated by InstructGPT). Both require careful consideration of data collection, model architecture, objective functions, and evaluation metrics.
Codex: Fine-tuning for Code Generation
The article emphasizes the inadequacy of traditional metrics like BLEU score for evaluating code generation. It introduces "functional correctness" and the pass@k metric, offering a more robust evaluation method. The creation of the HumanEval dataset, comprising hand-written programming problems with unit tests, is also highlighted. Data cleaning strategies specific to code are discussed, along with the importance of adapting tokenizers to handle the unique characteristics of programming languages (e.g., whitespace encoding). The article presents results demonstrating Codex's superior performance compared to GPT-3 on HumanEval and explores the impact of model size and temperature on performance.
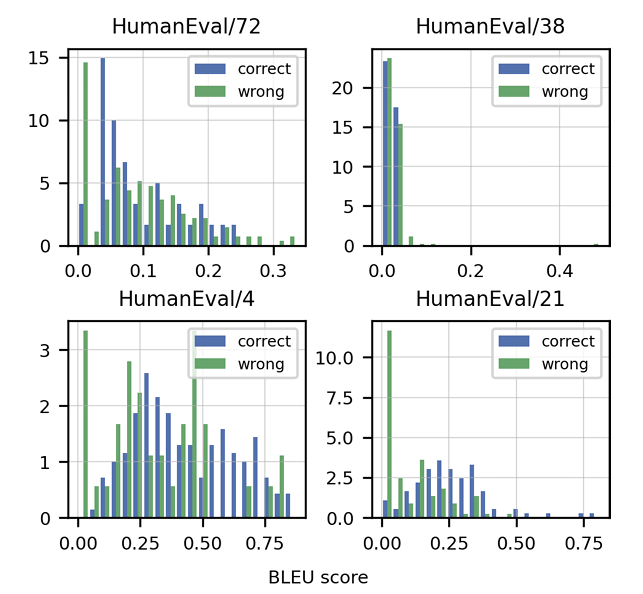


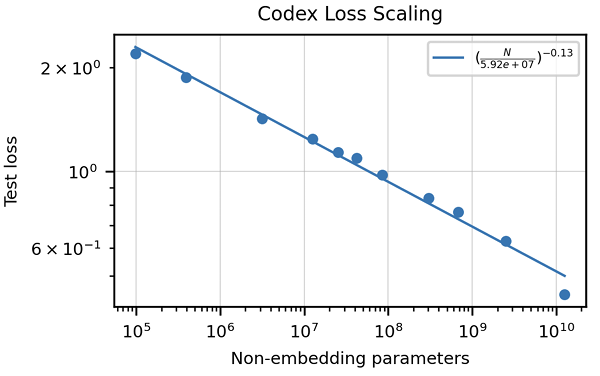
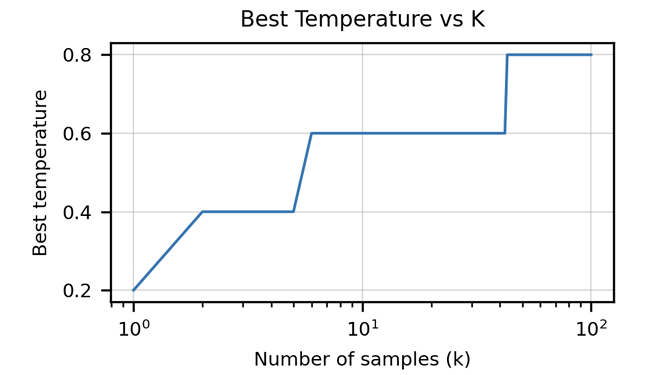
InstructGPT and ChatGPT: Aligning with Human Preferences
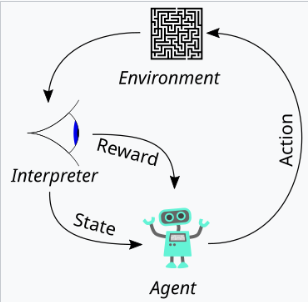
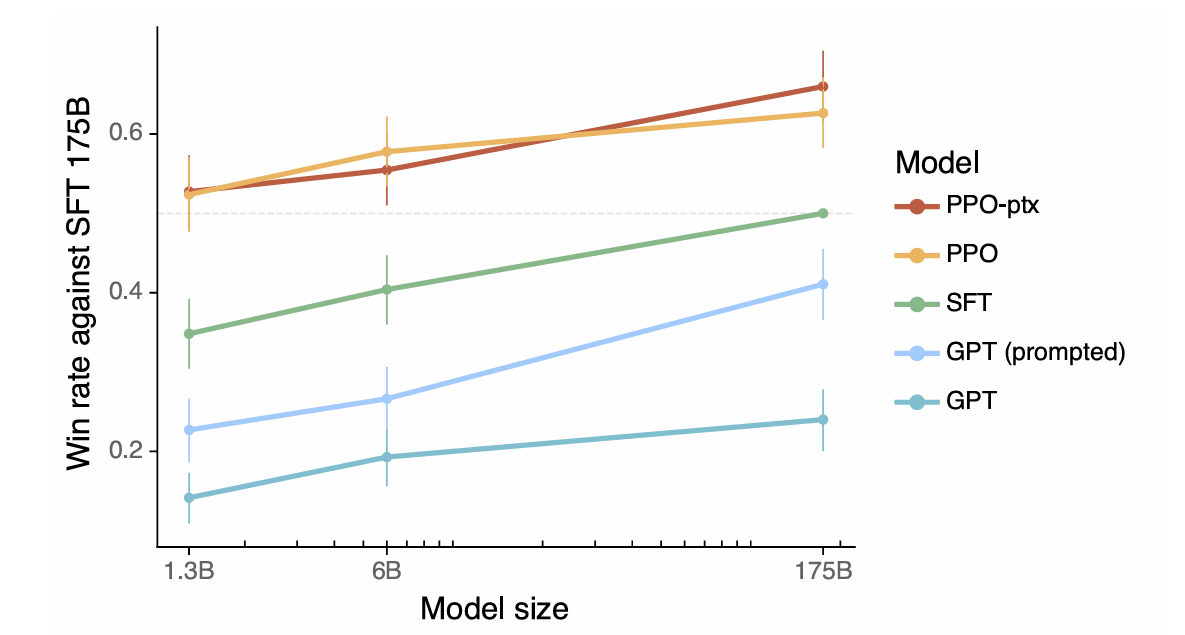
The article defines alignment as the model exhibiting helpfulness, honesty, and harmlessness. It explains how these qualities are translated into measurable aspects like instruction following, hallucination rate, and bias/toxicity. The use of Reinforcement Learning from Human Feedback (RLHF) is detailed, outlining the three stages: collecting human feedback, training a reward model, and optimizing the policy using Proximal Policy Optimization (PPO). The article emphasizes the importance of data quality control in the human feedback collection process. Results showcasing InstructGPT's improved alignment, reduced hallucination, and mitigation of performance regressions are presented.

Summary and Best Practices
The article concludes by summarizing key considerations for fine-tuning LLMs, including defining desired behaviors, evaluating performance, collecting and cleaning data, adapting model architecture, and mitigating potential negative consequences. It encourages careful consideration of hyperparameter tuning and emphasizes the iterative nature of the fine-tuning process.
The above is the detailed content of Understanding the Evolution of ChatGPT: Part 3- Insights from Codex and InstructGPT. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 AI Investor Stuck At A Standstill? 3 Strategic Paths To Buy, Build, Or Partner With AI Vendors
Jul 02, 2025 am 11:13 AM
AI Investor Stuck At A Standstill? 3 Strategic Paths To Buy, Build, Or Partner With AI Vendors
Jul 02, 2025 am 11:13 AM
Investing is booming, but capital alone isn’t enough. With valuations rising and distinctiveness fading, investors in AI-focused venture funds must make a key decision: Buy, build, or partner to gain an edge? Here’s how to evaluate each option—and pr
 The Unstoppable Growth Of Generative AI (AI Outlook Part 1)
Jun 21, 2025 am 11:11 AM
The Unstoppable Growth Of Generative AI (AI Outlook Part 1)
Jun 21, 2025 am 11:11 AM
Disclosure: My company, Tirias Research, has consulted for IBM, Nvidia, and other companies mentioned in this article.Growth driversThe surge in generative AI adoption was more dramatic than even the most optimistic projections could predict. Then, a
 AGI And AI Superintelligence Are Going To Sharply Hit The Human Ceiling Assumption Barrier
Jul 04, 2025 am 11:10 AM
AGI And AI Superintelligence Are Going To Sharply Hit The Human Ceiling Assumption Barrier
Jul 04, 2025 am 11:10 AM
Let’s talk about it. This analysis of an innovative AI breakthrough is part of my ongoing Forbes column coverage on the latest in AI, including identifying and explaining various impactful AI complexities (see the link here). Heading Toward AGI And
 Build Your First LLM Application: A Beginner's Tutorial
Jun 24, 2025 am 10:13 AM
Build Your First LLM Application: A Beginner's Tutorial
Jun 24, 2025 am 10:13 AM
Have you ever tried to build your own Large Language Model (LLM) application? Ever wondered how people are making their own LLM application to increase their productivity? LLM applications have proven to be useful in every aspect
 AMD Keeps Building Momentum In AI, With Plenty Of Work Still To Do
Jun 28, 2025 am 11:15 AM
AMD Keeps Building Momentum In AI, With Plenty Of Work Still To Do
Jun 28, 2025 am 11:15 AM
Overall, I think the event was important for showing how AMD is moving the ball down the field for customers and developers. Under Su, AMD’s M.O. is to have clear, ambitious plans and execute against them. Her “say/do” ratio is high. The company does
 Kimi K2: The Most Powerful Open-Source Agentic Model
Jul 12, 2025 am 09:16 AM
Kimi K2: The Most Powerful Open-Source Agentic Model
Jul 12, 2025 am 09:16 AM
Remember the flood of open-source Chinese models that disrupted the GenAI industry earlier this year? While DeepSeek took most of the headlines, Kimi K1.5 was one of the prominent names in the list. And the model was quite cool.
 Future Forecasting A Massive Intelligence Explosion On The Path From AI To AGI
Jul 02, 2025 am 11:19 AM
Future Forecasting A Massive Intelligence Explosion On The Path From AI To AGI
Jul 02, 2025 am 11:19 AM
Let’s talk about it. This analysis of an innovative AI breakthrough is part of my ongoing Forbes column coverage on the latest in AI, including identifying and explaining various impactful AI complexities (see the link here). For those readers who h
 7 Key Highlights from Geoffrey Hinton on Superintelligent AI - Analytics Vidhya
Jun 21, 2025 am 10:54 AM
7 Key Highlights from Geoffrey Hinton on Superintelligent AI - Analytics Vidhya
Jun 21, 2025 am 10:54 AM
If the Godfather of AI tells you to “train to be a plumber,” you know it’s worth listening to—at least that’s what caught my attention. In a recent discussion, Geoffrey Hinton talked about the potential future shaped by superintelligent AI, and if yo
