

Full record of writing python crawlers from scratch_python
Apr 08, 2018 am 11:52 AM
The first nine articles have been introduced in detail from the basics to the writing. The tenth article is about being perfect, so we will record in detail how to write a crawler program step by step. Please read it. Be careful
First let’s talk about our school’s website:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html
Check results You need to log in, and then the results of each subject are displayed, but only the results are displayed without the grade points, which is the weighted average score.
Obviously calculating grade points manually is a very troublesome thing. So we can use python to make a crawler to solve this problem.
1. On the eve of the decisive battle
Let’s prepare a tool first: HttpFox plug-in.
This is an http protocol analysis plug-in that analyzes page request and response time, content, and COOKIE used by the browser.
Take me as an example, just install it on Firefox, the effect is as shown: 
You can view the corresponding information very intuitively.
Click start to start detection, click stop to pause detection, and click clear to clear the content.
Generally before use, click stop to pause, and then click clear to clear the screen to ensure that you see the data obtained by accessing the current page.
2. Go deep behind enemy lines
Let’s go to the score inquiry website of Shandong University to see what was sent when logging in. information.
First go to the login page, open httpfox, after clearing, click start to turn on the detection:

After entering the personal information, make sure httpfox is turned on. Then click OK to submit the information and log in.
You can see at this time that httpfox has detected three pieces of information:
At this time, click the stop button to ensure that what is captured is the feedback after visiting the page. Data so that we can simulate login when doing crawlers.
3. Pao Ding Jie Niu
At first glance, we got three data, two are GET and one is POST, but what exactly are they? How to use it, we still don’t know.
So, we need to check the captured content one by one.
Look at the POST information first:
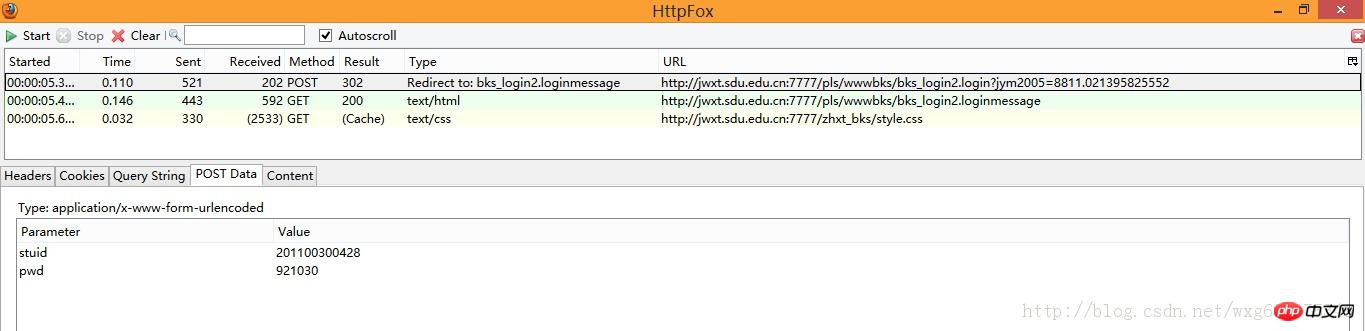
Since it is the POST information, we can just look at the PostData.
You can see that there are two POST data, studid and pwd.
And it can be seen from the Redirect to of Type that after the POST is completed, it jumps to the bks_login2.loginmessage page.
It can be seen that this data is the form data submitted after clicking OK.
Click on the cookie label to see the cookie information:
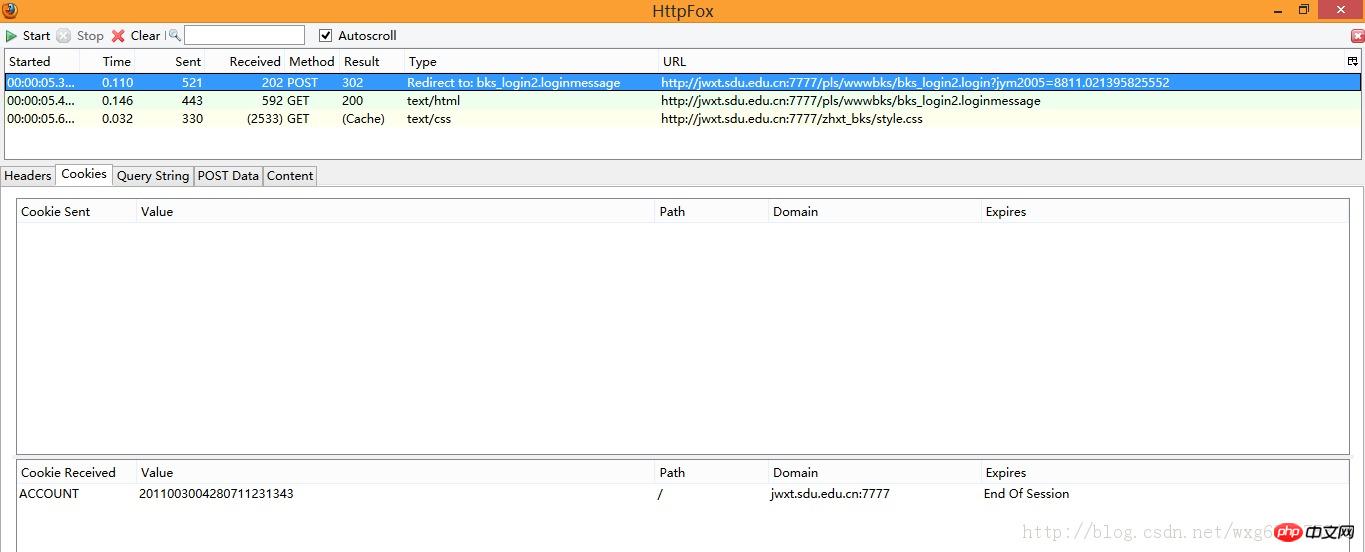
Yes, an ACCOUNT cookie was received and will be automatically destroyed after the session ends. .
So what information did you receive after submitting?
Let’s take a look at the next two GET data.
Look at the first one first. We click on the content tag to view the received content. Do you feel like eating it alive? -The HTML source code is undoubtedly exposed:
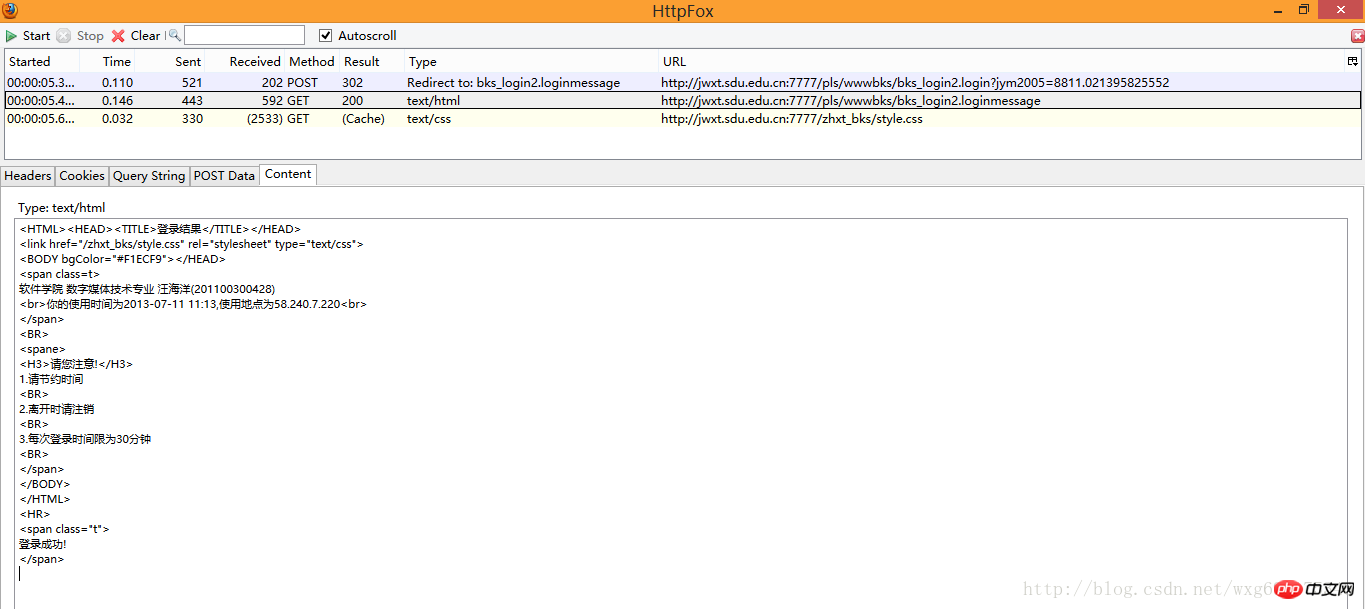
It seems that this is just the html source code of the page. Click on the cookie to view the cookie-related information:
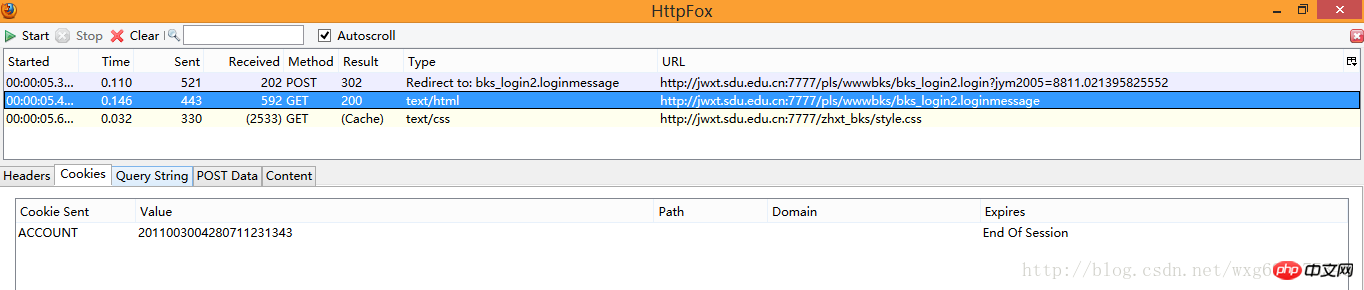
Aha, it turns out that the content of the html page was received only after the cookie information was sent.
Let’s take a look at the last received message:
After a rough look, it should be just a css file called style.css, which doesn’t mean much to us. big effect.
4. Calmly respond
Now that we know what data we sent to the server and what data we received, the basic process is as follows :
First, we POST the student ID and password--->Then return the cookie value and then send the cookie to the server--->Return the page information. Obtain the data from the grades page, use regular expressions to extract the grades and credits separately and calculate the weighted average.
OK, it looks like a very simple sample paper. Then let’s try it out.
But before the experiment, there is still an unresolved problem, which is where is the POST data sent?
Look at the original page again:

It is obviously implemented using an html framework, that is to say, the address we see in the address bar is not the address to submit the form on the right.
So how can we get the real address-. -Right-click to view the page source code:
Yes, that name="w_right" is the login page we want.
The original address of the website is:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html
So, the real form submission The address should be:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/xk_login.html
After entering it, it is true:
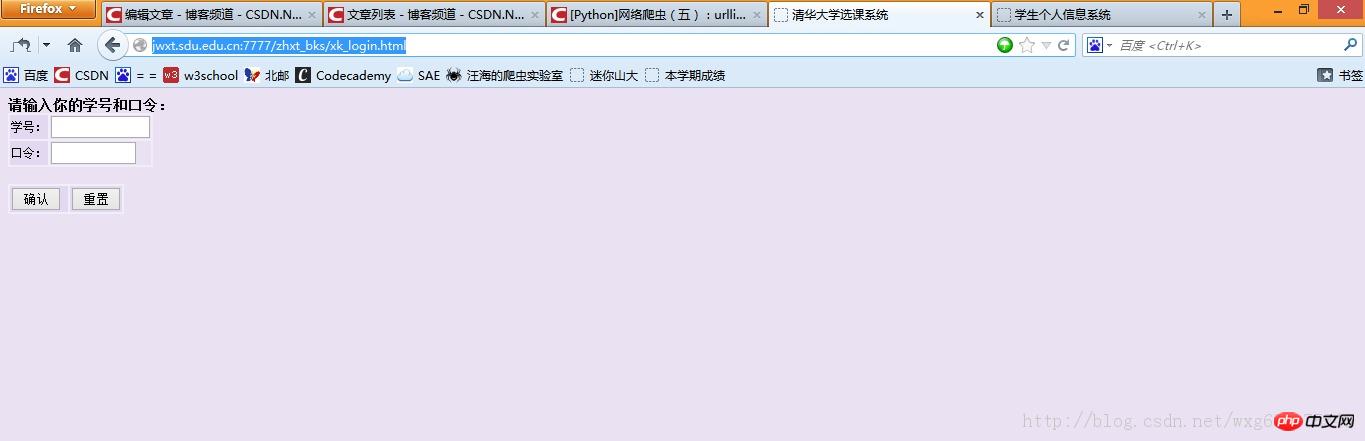
It’s actually the course selection system of Tsinghua University. . . My guess is that our school was too lazy to create a page, so we just borrowed it. . As a result, the title was not even changed. . .
But this page is still not the page we need, because the page our POST data is submitted to should be the page submitted in the ACTION of the form.
In other words, we need to check the source code to know where the POST data is sent:
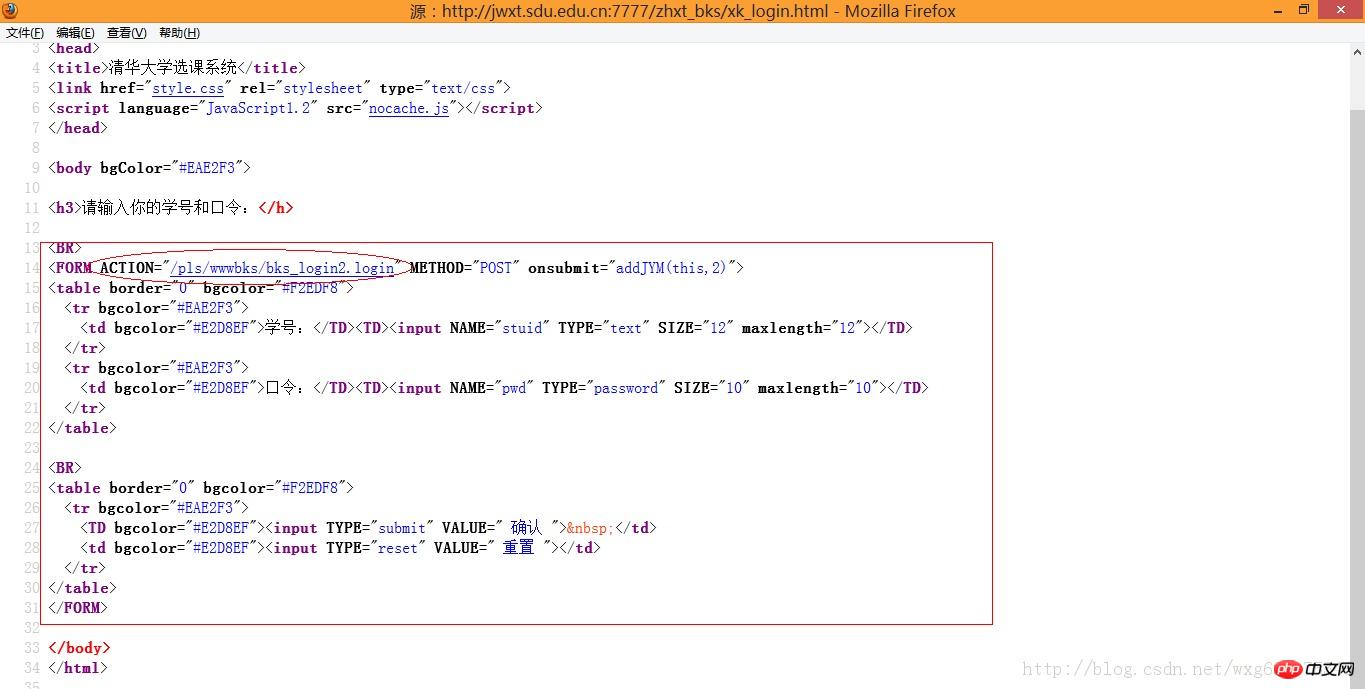
Well, visually this is the POST submission The address of the data.
Arrange it into the address bar. The complete address should be as follows:
http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login
(The way to obtain it is very simple. Just click on the link in Firefox browser to see the address of the link)
5. Try it out
The next task is to use python to simulate sending a POST data and get the returned cookie value.
For the operation of cookies, you can read this blog post:
http://www.jb51.net/article/57144.htm
We first prepare a POST data, then prepare a cookie to receive, and then write the source code as follows:
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山東大學(xué)爬蟲(chóng)
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 語(yǔ)言:Python 2.7
# 操作:輸入學(xué)號(hào)和密碼
# 功能:輸出成績(jī)的加權(quán)平均值也就是績(jī)點(diǎn)
#---------------------------------------
import urllib
import urllib2
import cookielib
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#需要POST的數(shù)據(jù)#
postdata=urllib.urlencode({
'stuid':'201100300428',
'pwd':'921030'
})
#自定義一個(gè)請(qǐng)求#
req = urllib2.Request(
url = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login',
data = postdata
)
#訪問(wèn)該鏈接#
result = opener.open(req)
#打印返回的內(nèi)容#
print result.read()After this, look at the effect of the operation:
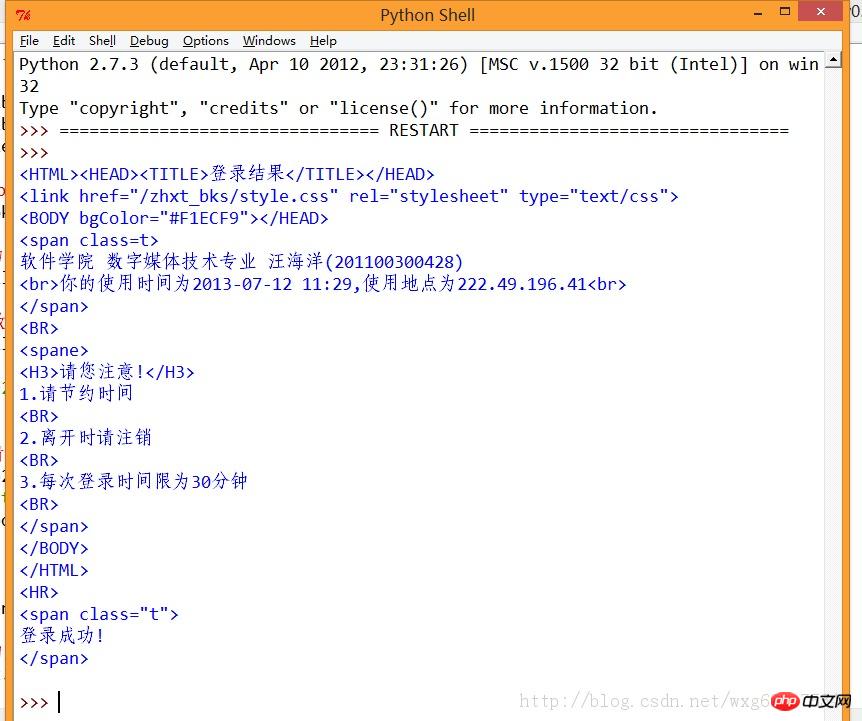
ok, in this way, we can calculate that the simulated login is successful.
6. Stealing the day and changing the day
The next task is to use a crawler to obtain the students’ scores.
Let’s take a look at the source website.
After opening HTTPFOX, click to view the results and find that the following data has been captured:
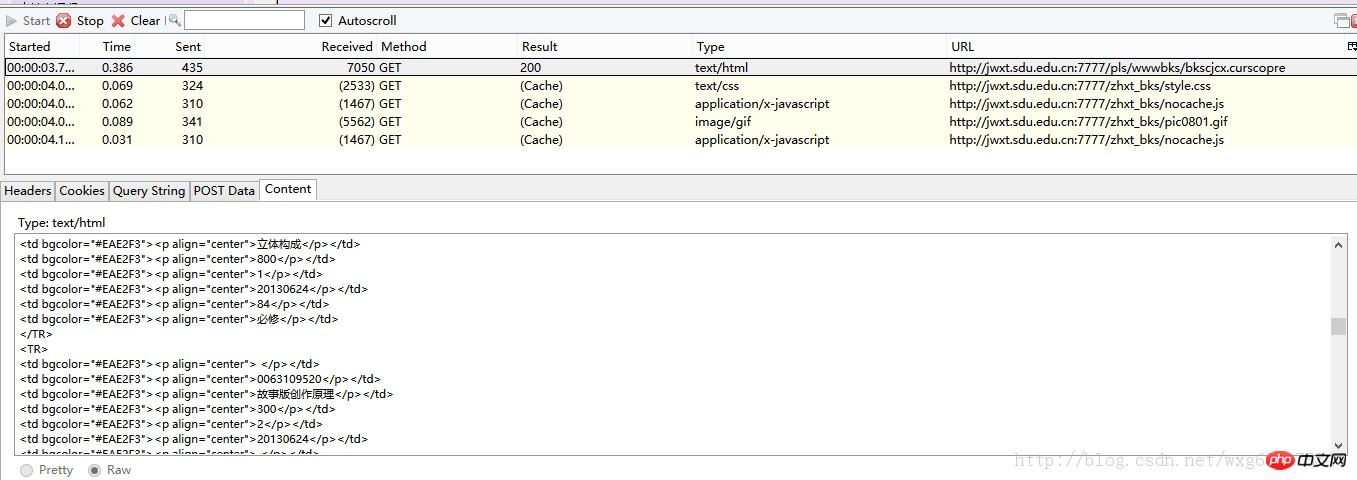
Click on the first GET data to view the content It is found that Content is the content of the obtained score.
For the obtained page link, right-click to view the element from the page source code, and you can see the page that jumps after clicking the link (in Firefox, you only need to right-click and "View this frame". ):
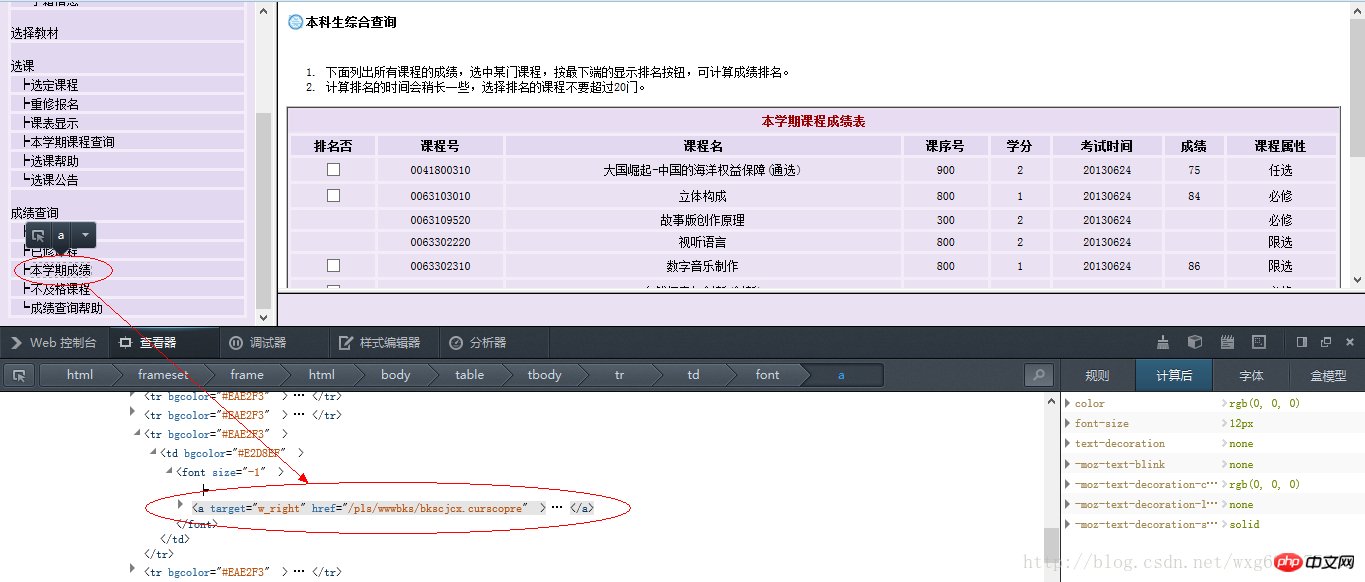
You can get the link to view the results as follows:
http://jwxt.sdu.edu.cn: 7777/pls/wwwbks/bkscjcx.curscopre
7. Everything is ready
Now everything is ready, so just apply the link to the crawler , see if you can view the results page.
As you can see from httpfox, we have to send a cookie to return the score information, so we use python to simulate the sending of a cookie to request the score information:
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山東大學(xué)爬蟲(chóng)
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 語(yǔ)言:Python 2.7
# 操作:輸入學(xué)號(hào)和密碼
# 功能:輸出成績(jī)的加權(quán)平均值也就是績(jī)點(diǎn)
#---------------------------------------
import urllib
import urllib2
import cookielib
#初始化一個(gè)CookieJar來(lái)處理Cookie的信息#
cookie = cookielib.CookieJar()
#創(chuàng)建一個(gè)新的opener來(lái)使用我們的CookieJar#
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#需要POST的數(shù)據(jù)#
postdata=urllib.urlencode({
'stuid':'201100300428',
'pwd':'921030'
})
#自定義一個(gè)請(qǐng)求#
req = urllib2.Request(
url = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login',
data = postdata
)
#訪問(wèn)該鏈接#
result = opener.open(req)
#打印返回的內(nèi)容#
print result.read()
#打印cookie的值
for item in cookie:
print 'Cookie:Name = '+item.name
print 'Cookie:Value = '+item.value
#訪問(wèn)該鏈接#
result = opener.open('http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre')
#打印返回的內(nèi)容#
print result.read()Press Just run F5 and take a look at the captured data:

Since there is no problem, use regular expressions to process the data a little bit , just take out the credits and corresponding scores.
8. Get it at your fingertips
Such a large amount of html source code is obviously not conducive to our processing. Next, we need to use regular expressions to extract the necessary data. .
For tutorials on regular expressions, you can read this blog post:
http://www.jb51.net/article/57150.htm
Let’s take a look at the results Source code:
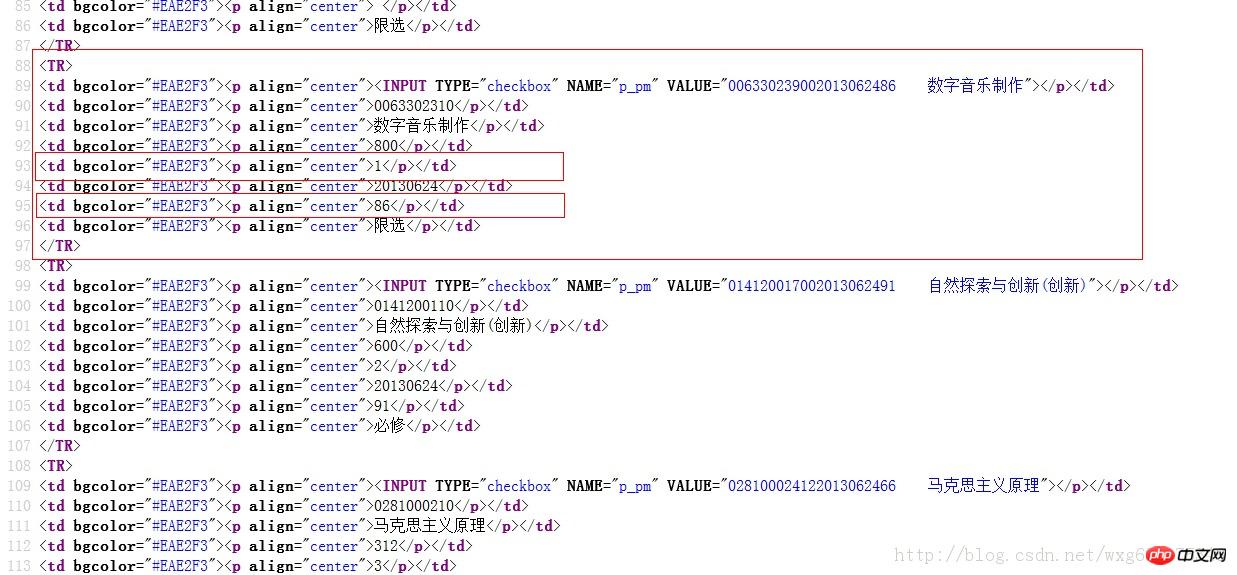
In this case, using regular expressions is easy.
We will tidy up the code a little, and then use regular expressions to extract the data:
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山東大學(xué)爬蟲(chóng)
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 語(yǔ)言:Python 2.7
# 操作:輸入學(xué)號(hào)和密碼
# 功能:輸出成績(jī)的加權(quán)平均值也就是績(jī)點(diǎn)
#---------------------------------------
import urllib
import urllib2
import cookielib
import re
class SDU_Spider:
# 申明相關(guān)的屬性
def __init__(self):
self.loginUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login' # 登錄的url
self.resultUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre' # 顯示成績(jī)的url
self.cookieJar = cookielib.CookieJar() # 初始化一個(gè)CookieJar來(lái)處理Cookie的信息
self.postdata=urllib.urlencode({'stuid':'201100300428','pwd':'921030'}) # POST的數(shù)據(jù)
self.weights = [] #存儲(chǔ)權(quán)重,也就是學(xué)分
self.points = [] #存儲(chǔ)分?jǐn)?shù),也就是成績(jī)
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookieJar))
def sdu_init(self):
# 初始化鏈接并且獲取cookie
myRequest = urllib2.Request(url = self.loginUrl,data = self.postdata) # 自定義一個(gè)請(qǐng)求
result = self.opener.open(myRequest) # 訪問(wèn)登錄頁(yè)面,獲取到必須的cookie的值
result = self.opener.open(self.resultUrl) # 訪問(wèn)成績(jī)頁(yè)面,獲得成績(jī)的數(shù)據(jù)
# 打印返回的內(nèi)容
# print result.read()
self.deal_data(result.read().decode('gbk'))
self.print_data(self.weights);
self.print_data(self.points);
# 將內(nèi)容從頁(yè)面代碼中摳出來(lái)
def deal_data(self,myPage):
myItems = re.findall('<TR>.*?<p.*?<p.*?<p.*?<p.*?<p.*?>(.*?)</p>.*?<p.*?<p.*?>(.*?)</p>.*?</TR>',myPage,re.S) #獲取到學(xué)分
for item in myItems:
self.weights.append(item[0].encode('gbk'))
self.points.append(item[1].encode('gbk'))
# 將內(nèi)容從頁(yè)面代碼中摳出來(lái)
def print_data(self,items):
for item in items:
print item
#調(diào)用
mySpider = SDU_Spider()
mySpider.sdu_init()The level is limited, and regular expressions are a bit ugly. The running effect is as shown in the figure:
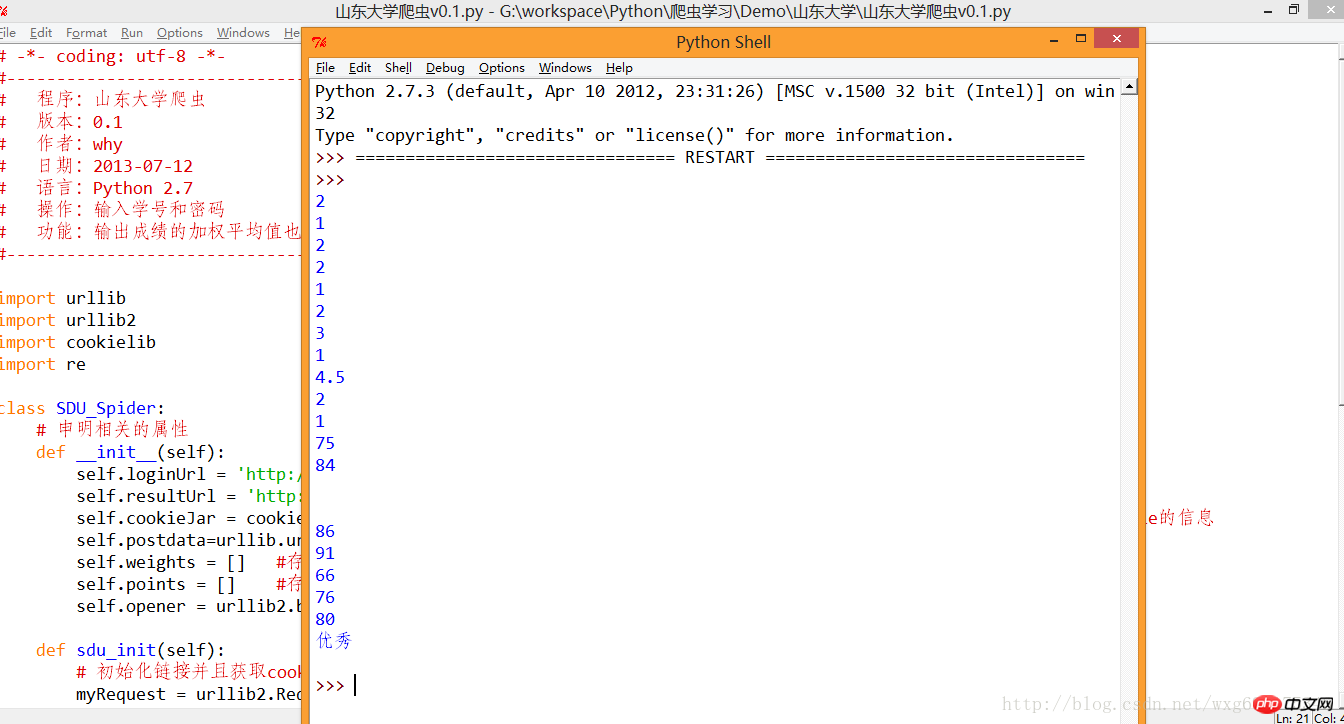
#ok, the next thing is just the data processing problem. .
9. Return in triumph
The complete code is as follows. At this point, a complete crawler project is completed.
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山東大學(xué)爬蟲(chóng)
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 語(yǔ)言:Python 2.7
# 操作:輸入學(xué)號(hào)和密碼
# 功能:輸出成績(jī)的加權(quán)平均值也就是績(jī)點(diǎn)
#---------------------------------------
import urllib
import urllib2
import cookielib
import re
import string
class SDU_Spider:
# 申明相關(guān)的屬性
def __init__(self):
self.loginUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login' # 登錄的url
self.resultUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre' # 顯示成績(jī)的url
self.cookieJar = cookielib.CookieJar() # 初始化一個(gè)CookieJar來(lái)處理Cookie的信息
self.postdata=urllib.urlencode({'stuid':'201100300428','pwd':'921030'}) # POST的數(shù)據(jù)
self.weights = [] #存儲(chǔ)權(quán)重,也就是學(xué)分
self.points = [] #存儲(chǔ)分?jǐn)?shù),也就是成績(jī)
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookieJar))
def sdu_init(self):
# 初始化鏈接并且獲取cookie
myRequest = urllib2.Request(url = self.loginUrl,data = self.postdata) # 自定義一個(gè)請(qǐng)求
result = self.opener.open(myRequest) # 訪問(wèn)登錄頁(yè)面,獲取到必須的cookie的值
result = self.opener.open(self.resultUrl) # 訪問(wèn)成績(jī)頁(yè)面,獲得成績(jī)的數(shù)據(jù)
# 打印返回的內(nèi)容
# print result.read()
self.deal_data(result.read().decode('gbk'))
self.calculate_date();
# 將內(nèi)容從頁(yè)面代碼中摳出來(lái)
def deal_data(self,myPage):
myItems = re.findall('<TR>.*?<p.*?<p.*?<p.*?<p.*?<p.*?>(.*?)</p>.*?<p.*?<p.*?>(.*?)</p>.*?</TR>',myPage,re.S) #獲取到學(xué)分
for item in myItems:
self.weights.append(item[0].encode('gbk'))
self.points.append(item[1].encode('gbk'))
#計(jì)算績(jī)點(diǎn),如果成績(jī)還沒(méi)出來(lái),或者成績(jī)是優(yōu)秀良好,就不運(yùn)算該成績(jī)
def calculate_date(self):
point = 0.0
weight = 0.0
for i in range(len(self.points)):
if(self.points[i].isdigit()):
point += string.atof(self.points[i])*string.atof(self.weights[i])
weight += string.atof(self.weights[i])
print point/weight
#調(diào)用
mySpider = SDU_Spider()
mySpider.sdu_init()Related recommendations:
How to use Python crawlers to obtain those valuable blog posts
Example sharing of python dynamic crawlers
The above is the detailed content of Full record of writing python crawlers from scratch_python. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to handle API authentication in Python
Jul 13, 2025 am 02:22 AM
How to handle API authentication in Python
Jul 13, 2025 am 02:22 AM
The key to dealing with API authentication is to understand and use the authentication method correctly. 1. APIKey is the simplest authentication method, usually placed in the request header or URL parameters; 2. BasicAuth uses username and password for Base64 encoding transmission, which is suitable for internal systems; 3. OAuth2 needs to obtain the token first through client_id and client_secret, and then bring the BearerToken in the request header; 4. In order to deal with the token expiration, the token management class can be encapsulated and automatically refreshed the token; in short, selecting the appropriate method according to the document and safely storing the key information is the key.
 How to test an API with Python
Jul 12, 2025 am 02:47 AM
How to test an API with Python
Jul 12, 2025 am 02:47 AM
To test the API, you need to use Python's Requests library. The steps are to install the library, send requests, verify responses, set timeouts and retry. First, install the library through pipinstallrequests; then use requests.get() or requests.post() and other methods to send GET or POST requests; then check response.status_code and response.json() to ensure that the return result is in compliance with expectations; finally, add timeout parameters to set the timeout time, and combine the retrying library to achieve automatic retry to enhance stability.
 Python variable scope in functions
Jul 12, 2025 am 02:49 AM
Python variable scope in functions
Jul 12, 2025 am 02:49 AM
In Python, variables defined inside a function are local variables and are only valid within the function; externally defined are global variables that can be read anywhere. 1. Local variables are destroyed as the function is executed; 2. The function can access global variables but cannot be modified directly, so the global keyword is required; 3. If you want to modify outer function variables in nested functions, you need to use the nonlocal keyword; 4. Variables with the same name do not affect each other in different scopes; 5. Global must be declared when modifying global variables, otherwise UnboundLocalError error will be raised. Understanding these rules helps avoid bugs and write more reliable functions.
 Python FastAPI tutorial
Jul 12, 2025 am 02:42 AM
Python FastAPI tutorial
Jul 12, 2025 am 02:42 AM
To create modern and efficient APIs using Python, FastAPI is recommended; it is based on standard Python type prompts and can automatically generate documents, with excellent performance. After installing FastAPI and ASGI server uvicorn, you can write interface code. By defining routes, writing processing functions, and returning data, APIs can be quickly built. FastAPI supports a variety of HTTP methods and provides automatically generated SwaggerUI and ReDoc documentation systems. URL parameters can be captured through path definition, while query parameters can be implemented by setting default values ??for function parameters. The rational use of Pydantic models can help improve development efficiency and accuracy.
 How to parse large JSON files in Python?
Jul 13, 2025 am 01:46 AM
How to parse large JSON files in Python?
Jul 13, 2025 am 01:46 AM
How to efficiently handle large JSON files in Python? 1. Use the ijson library to stream and avoid memory overflow through item-by-item parsing; 2. If it is in JSONLines format, you can read it line by line and process it with json.loads(); 3. Or split the large file into small pieces and then process it separately. These methods effectively solve the memory limitation problem and are suitable for different scenarios.
 Python for loop over a tuple
Jul 13, 2025 am 02:55 AM
Python for loop over a tuple
Jul 13, 2025 am 02:55 AM
In Python, the method of traversing tuples with for loops includes directly iterating over elements, getting indexes and elements at the same time, and processing nested tuples. 1. Use the for loop directly to access each element in sequence without managing the index; 2. Use enumerate() to get the index and value at the same time. The default index is 0, and the start parameter can also be specified; 3. Nested tuples can be unpacked in the loop, but it is necessary to ensure that the subtuple structure is consistent, otherwise an unpacking error will be raised; in addition, the tuple is immutable and the content cannot be modified in the loop. Unwanted values can be ignored by \_. It is recommended to check whether the tuple is empty before traversing to avoid errors.
 What are python default arguments and their potential issues?
Jul 12, 2025 am 02:39 AM
What are python default arguments and their potential issues?
Jul 12, 2025 am 02:39 AM
Python default parameters are evaluated and fixed values ??when the function is defined, which can cause unexpected problems. Using variable objects such as lists as default parameters will retain modifications, and it is recommended to use None instead; the default parameter scope is the environment variable when defined, and subsequent variable changes will not affect their value; avoid relying on default parameters to save state, and class encapsulation state should be used to ensure function consistency.
 What is a pure function in Python
Jul 14, 2025 am 12:18 AM
What is a pure function in Python
Jul 14, 2025 am 12:18 AM
Pure functions in Python refer to functions that always return the same output with no side effects given the same input. Its characteristics include: 1. Determinism, that is, the same input always produces the same output; 2. No side effects, that is, no external variables, no input data, and no interaction with the outside world. For example, defadd(a,b):returna b is a pure function because no matter how many times add(2,3) is called, it always returns 5 without changing other content in the program. In contrast, functions that modify global variables or change input parameters are non-pure functions. The advantages of pure functions are: easier to test, more suitable for concurrent execution, cache results to improve performance, and can be well matched with functional programming tools such as map() and filter().
