


In Linux, a handle is an identifier, a reference identifier managed by the system. The kernel can use the handle to calculate the address of the file object in the kernel; as long as the developer obtains the handle of the object, it can The object performs arbitrary operations.

#The operating environment of this tutorial: linux5.9.8 system, Dell G3 computer.
What is a handle
A handle is an identifier. As long as we get the handle of the object, we can perform any operation on the object.
The handle is not a pointer. The operating system can use the handle to find a piece of memory. This handle may be an identifier, a map key, or a pointer. It depends on how the operating system handles it. fd can be regarded as replacing handles to some extent; Linux has corresponding mechanisms, but there is no unified handle type. Various types of system resources are identified by their respective types and operated by their respective interfaces.
At the operating system level, file operations also have a concept similar to FILE. In Linux, this is called a file descriptor (File Descriptor), and in Windows, it is called a handle (Handle) (not mentioned below) When ambiguous, they are collectively referred to as handles). The user opens the file through a certain function to obtain a handle, and thereafter the user manipulates the file through the handle.
Rough explanation
windows is handle, liunx is similar to fd, in the earliest windows development book, handle is translated as " handle". Although it doesn't sound good, I personally think it is quite expressive.
Although you are only holding the handle, you can pull the entire door, and you don’t have to care about what the door looks like
If a door has multiple handles, they can be pulled by different people. (Process) Hold it, it’s hard to say where the door will go.
The reason for designing such a handle is that the handle can prevent users from reading and writing file objects in the operating system kernel at will. Whether it is Linux or Windows, the file handle is always associated with the kernel's file object, but the details of the association are not visible to the user. The kernel can calculate the address of the file object in the kernel through the handle, but this ability is not open to users.
Handle in liunx
In the Linux system design, we follow the principle that everything is a file, that is, disk files, directories, network sockets Connectors, disks, pipes, etc., all of which are files, will return an fd when we open it, which is a file handle.
If you open files frequently or open a network socket and forget to release it, the handle will be leaked.
In the Linux system, there is a limit on the number of file handles that a process can call. By default, the maximum number of file handles that each process can call is 1024. If this limit is exceeded, the process will not be able to obtain new files. handle, resulting in the inability to open new files or network sockets, and the online server will be denied service.
The following is a practical example. In Linux, fd with values ????0, 1, and 2 represent standard input, standard output, and standard error output respectively. The fd obtained by opening the file in the program starts to grow from 3.
What exactly is fd?
In the kernel, each process has a private "open file table". This table is an array of pointers, and each element points to a kernel. The open file object.
And fd is the subscript of this table. When the user opens a file, the kernel will internally generate an open file object, find an empty item in this table, let this item point to the generated open file object, and return the subscript of this item as fd.
Since this table is in the kernel and cannot be accessed by users, even if the user owns fd, he cannot get the address of the open file object and can only operate it through the functions provided by the system.
In C language, the channel for manipulating files is the FILE structure. It is not difficult to imagine that the FILE structure in C language must have a one-to-one relationship with fd. Each FILE structure will record its own unique corresponding fd. .
In programming, a handle is a special smart pointer. When an application wants to reference memory blocks or objects managed by other systems (such as databases and operating systems), handles are used.
The difference between a handle and an ordinary pointer is that the pointer contains the memory address of the referenced object, while the handle is a reference identifier managed by the system, which can be relocated to a memory address by the system. This indirect object access mode enhances the system's control over the referenced object.
In the memory management of operating systems (such as Mac OS and Windows) in the 1980s, handles were widely used. File descriptors in Unix systems are basically handles. Like other desktop environments, the Windows API makes extensive use of handles to identify objects in the system and establish communication channels between the operating system and user space. For example, a form on the desktop is identified by a handle of type HWND.
Today, increases in memory capacity and virtual memory algorithms have made simpler pointers more popular, while handles that point to another pointer have fallen out of favor. Despite this, many operating systems still refer to pointers to private objects and internal array indices that a process passes to the client as handles.
Related recommendations: "Linux Video Tutorial"
The above is the detailed content of what is linux handle. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Postman Integrated Application on CentOS
May 19, 2025 pm 08:00 PM
Postman Integrated Application on CentOS
May 19, 2025 pm 08:00 PM
Integrating Postman applications on CentOS can be achieved through a variety of methods. The following are the detailed steps and suggestions: Install Postman by downloading the installation package to download Postman's Linux version installation package: Visit Postman's official website and select the version suitable for Linux to download. Unzip the installation package: Use the following command to unzip the installation package to the specified directory, for example /opt: sudotar-xzfpostman-linux-x64-xx.xx.xx.tar.gz-C/opt Please note that "postman-linux-x64-xx.xx.xx.tar.gz" is replaced by the file name you actually downloaded. Create symbols
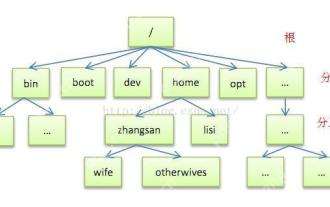 Detailed introduction to each directory of Linux and each directory (reprinted)
May 22, 2025 pm 07:54 PM
Detailed introduction to each directory of Linux and each directory (reprinted)
May 22, 2025 pm 07:54 PM
[Common Directory Description] Directory/bin stores binary executable files (ls, cat, mkdir, etc.), and common commands are generally here. /etc stores system management and configuration files/home stores all user files. The root directory of the user's home directory is the basis of the user's home directory. For example, the home directory of the user user is /home/user. You can use ~user to represent /usr to store system applications. The more important directory /usr/local Local system administrator software installation directory (install system-level applications). This is the largest directory, and almost all the applications and files to be used are in this directory. /usr/x11r6?Directory for storing x?window/usr/bin?Many
 How to manually install plugin packages in VSCode
May 15, 2025 pm 09:33 PM
How to manually install plugin packages in VSCode
May 15, 2025 pm 09:33 PM
The steps to manually install the plug-in package in VSCode are: 1. Download the .vsix file of the plug-in; 2. Open VSCode and press Ctrl Shift P (Windows/Linux) or Cmd Shift P (Mac) to call up the command panel; 3. Enter and select Extensions:InstallfromVSIX..., then select .vsix file and install. Manually installing plug-ins provides a flexible way to install, especially when the network is restricted or the plug-in market is unavailable, but attention needs to be paid to file security and possible dependencies.
 Where is the pycharm interpreter?
May 23, 2025 pm 10:09 PM
Where is the pycharm interpreter?
May 23, 2025 pm 10:09 PM
Setting the location of the interpreter in PyCharm can be achieved through the following steps: 1. Open PyCharm, click the "File" menu, and select "Settings" or "Preferences". 2. Find and click "Project:[Your Project Name]" and select "PythonInterpreter". 3. Click "AddInterpreter", select "SystemInterpreter", browse to the Python installation directory, select the Python executable file, and click "OK". When setting up the interpreter, you need to pay attention to path correctness, version compatibility and the use of the virtual environment to ensure the smooth operation of the project.
 The difference between programming in Java and other languages ??Analysis of the advantages of cross-platform features of Java
May 20, 2025 pm 08:21 PM
The difference between programming in Java and other languages ??Analysis of the advantages of cross-platform features of Java
May 20, 2025 pm 08:21 PM
The main difference between Java and other programming languages ??is its cross-platform feature of "writing at once, running everywhere". 1. The syntax of Java is close to C, but it removes pointer operations that are prone to errors, making it suitable for large enterprise applications. 2. Compared with Python, Java has more advantages in performance and large-scale data processing. The cross-platform advantage of Java stems from the Java virtual machine (JVM), which can run the same bytecode on different platforms, simplifying development and deployment, but be careful to avoid using platform-specific APIs to maintain cross-platformity.
 After installing Nginx, the configuration file path and initial settings
May 16, 2025 pm 10:54 PM
After installing Nginx, the configuration file path and initial settings
May 16, 2025 pm 10:54 PM
Understanding Nginx's configuration file path and initial settings is very important because it is the first step in optimizing and managing a web server. 1) The configuration file path is usually /etc/nginx/nginx.conf. The syntax can be found and tested using the nginx-t command. 2) The initial settings include global settings (such as user, worker_processes) and HTTP settings (such as include, log_format). These settings allow customization and extension according to requirements. Incorrect configuration may lead to performance issues and security vulnerabilities.
 MySQL installation tutorial teach you step by step the detailed steps for installing and configuration of mySQL step by step
May 23, 2025 am 06:09 AM
MySQL installation tutorial teach you step by step the detailed steps for installing and configuration of mySQL step by step
May 23, 2025 am 06:09 AM
The installation and configuration of MySQL can be completed through the following steps: 1. Download the installation package suitable for the operating system from the official website. 2. Run the installer, select the "Developer Default" option and set the root user password. 3. After installation, configure environment variables to ensure that the bin directory of MySQL is in PATH. 4. When creating a user, follow the principle of minimum permissions and set a strong password. 5. Adjust the innodb_buffer_pool_size and max_connections parameters when optimizing performance. 6. Back up the database regularly and optimize query statements to improve performance.
 Comparison between Informix and MySQL on Linux
May 29, 2025 pm 11:21 PM
Comparison between Informix and MySQL on Linux
May 29, 2025 pm 11:21 PM
Informix and MySQL are both popular relational database management systems. They perform well in Linux environments and are widely used. The following is a comparison and analysis of the two on the Linux platform: Installing and configuring Informix: Deploying Informix on Linux requires downloading the corresponding installation files, and then completing the installation and configuration process according to the official documentation. MySQL: The installation process of MySQL is relatively simple, and can be easily installed through system package management tools (such as apt or yum), and there are a large number of tutorials and community support on the network for reference. Performance Informix: Informix has excellent performance and
