The basic unit of computer storage is the byte, which is composed of 8 bits. Since English only consists of 26 letters plus a number of symbols, English characters can be stored directly in bytes. But other languages ??(such as Chinese, Japanese, Korean, etc.) have to use multiple bytes for encoding due to the large number of characters.
With the spread of computer technology, non-Latin character encoding technology continues to develop, but there are still two major limitations:
Does not support multiple languages: The encoding scheme of one language cannot be used for another language
There is no unified standard: for example, Chinese has multiple encoding standards such as GBK, GB2312, GB18030
Because the encoding methods are not uniform, developers need to convert back and forth between different encodings, and many errors will inevitably occur. In order to solve this kind of inconsistency problem, the Unicode standard was proposed. Unicode organizes and encodes most of the writing systems in the world, allowing computers to process text in a unified way. Unicode currently contains more than 140,000 characters and naturally supports multiple languages. (Unicode’s uni is the root of “unification”)
2 Unicode in Python
2.1 Benefits of Unicode objects
After Python 3, Unicode is used internally in the str object Represents, and therefore becomes a Unicode object in the source code. The advantage of using Unicode representation is that the core logic of the program uses Unicode uniformly, and only needs to be decoded and encoded at the input and output layers, which can avoid various encoding problems to the greatest extent.
The diagram is as follows:
##2.2 Python’s optimization of UnicodeProblem: Since Unicode contains more than 140,000 characters, each A character requires at least 4 bytes to save (this is probably because 2 bytes are not enough, so 4 bytes are used, and 3 bytes are generally not used). The ASCII code for English characters requires only 1 byte. Using Unicode will quadruple the cost of frequently used English characters. First of all, let’s take a look at the size difference of different forms of str objects in Python:
It can be seen that Python internally optimizes Unicode objects: according to the text content, the underlying storage unit is selected . The underlying storage of Unicode objects is divided into three categories according to the Unicode code point range of text characters:
PyUnicode_1BYTE_KIND: All character code points are between U 0000 and U 00FF
PyUnicode_2BYTE_KIND: All character code points are between U 0000 and U FFFF, and at least one character has a code point greater than U 00FF
PyUnicode_1BYTE_KIND: All character code points are between U 0000 and U 10FFFF, and at least one character has a code point greater than U FFFF
##The corresponding enumeration is as follows:
enum PyUnicode_Kind {
/* String contains only wstr byte characters. This is only possible
when the string was created with a legacy API and _PyUnicode_Ready()
has not been called yet. */
PyUnicode_WCHAR_KIND = 0,
/* Return values of the PyUnicode_KIND() macro: */
PyUnicode_1BYTE_KIND = 1,
PyUnicode_2BYTE_KIND = 2,
PyUnicode_4BYTE_KIND = 4
};
According to different Classification, select different storage units:
/* Py_UCS4 and Py_UCS2 are typedefs for the respective
unicode representations. */
typedef uint32_t Py_UCS4;
typedef uint16_t Py_UCS2;
typedef uint8_t Py_UCS1;
The corresponding relationship is as follows:
Text type
Character storage unit
Character storage unit size (bytes)
PyUnicode_1BYTE_KIND
Py_UCS1
1
PyUnicode_2BYTE_KIND
Py_UCS2
2
PyUnicode_4BYTE_KIND
Py_UCS4
4
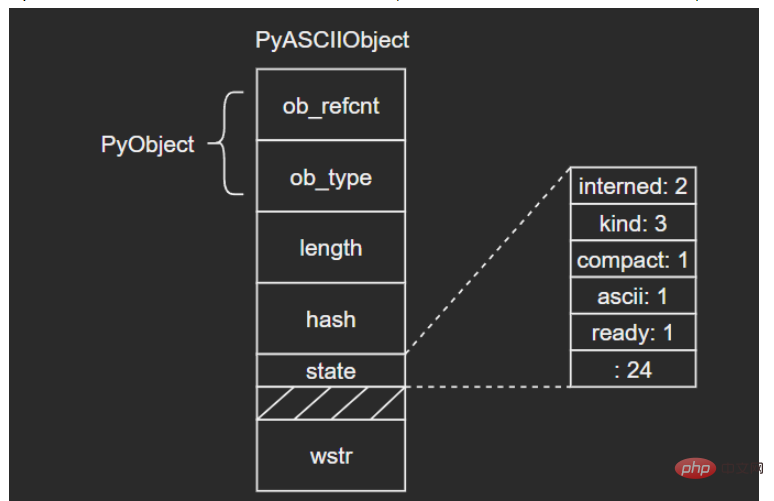
Since the Unicode internal storage structure varies depending on the text type, the type kind must be saved as a Unicode object public field. Python internally defines some flag bits as Unicode public fields: (Due to the author's limited level, all the fields here will not be introduced in the subsequent content. You can learn about it yourself later. Hold your fist~)
interned: Whether to maintain the interned mechanism
kind: type, used to distinguish the size of the underlying storage unit of characters
compact: memory allocation method, whether the object and the text buffer are separated
asscii: Whether the text is all pure ASCII
Through the PyUnicode_New function, according to the number of text characters size and the maximum character maxchar initializes the Unicode object. This function mainly selects the most compact character storage unit and underlying structure for Unicode objects based on maxchar: (The source code is relatively long, so it will not be listed here. You can understand it by yourself. It is shown in table form below)
maxchar < 128
128 <= maxchar < 256
256 <= maxchar < 65536
65536 <= maxchar < MAX_UNICODE
##kind
PyUnicode_1BYTE_KIND
PyUnicode_1BYTE_KIND
PyUnicode_2BYTE_KIND
PyUnicode_4BYTE_KIND
ascii
1
0
0
0
Character storage unit size (bytes)
1
1
2
4
Underlying structure
PyASCIIObject
PyCompactUnicodeObject
PyCompactUnicodeObject
PyCompactUnicodeObject
3 Unicode對(duì)象的底層結(jié)構(gòu)體
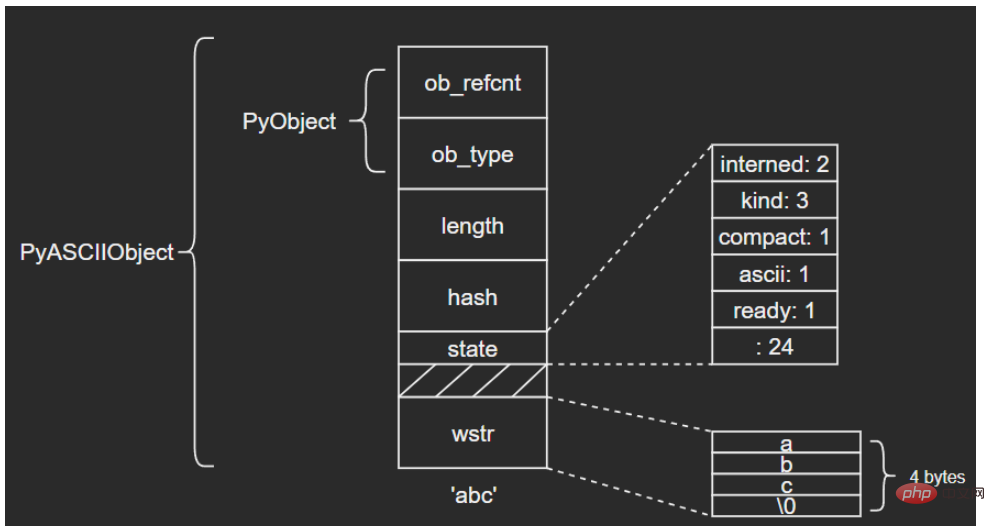
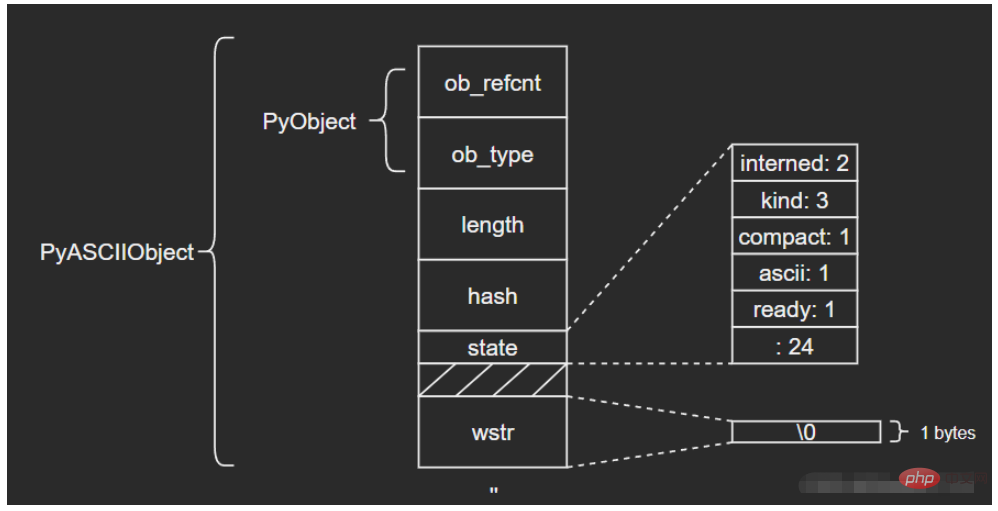
3.1 PyASCIIObject
C源碼:
typedef struct {
PyObject_HEAD
Py_ssize_t length; /* Number of code points in the string */
Py_hash_t hash; /* Hash value; -1 if not set */
struct {
unsigned int interned:2;
unsigned int kind:3;
unsigned int compact:1;
unsigned int ascii:1;
unsigned int ready:1;
unsigned int :24;
} state;
wchar_t *wstr; /* wchar_t representation (null-terminated) */
} PyASCIIObject;
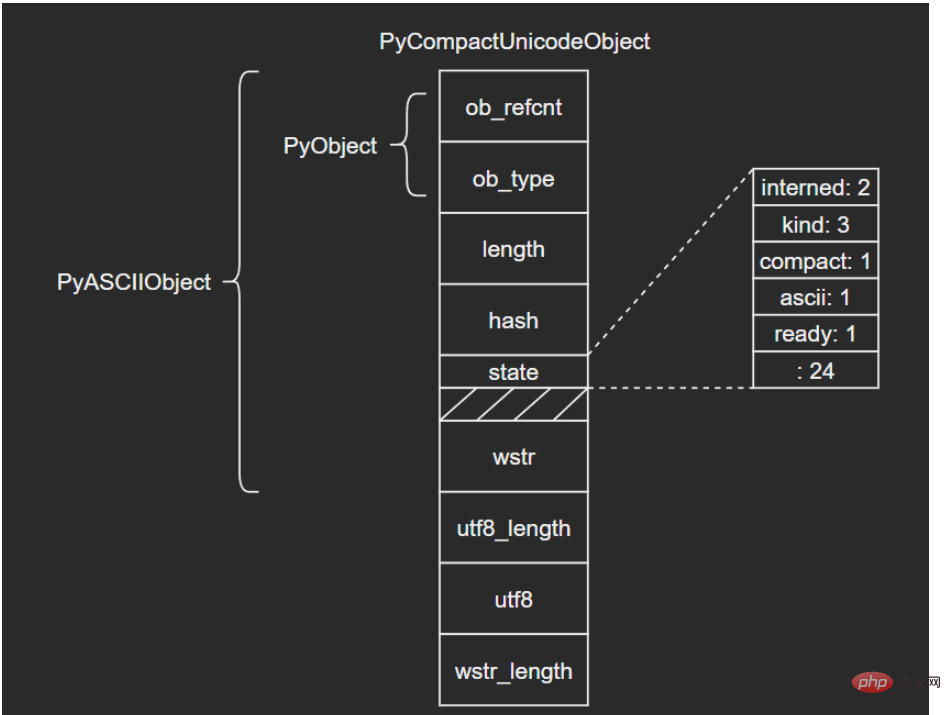
/* Non-ASCII strings allocated through PyUnicode_New use the
PyCompactUnicodeObject structure. state.compact is set, and the data
immediately follow the structure. */
typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length; /* Number of bytes in utf8, excluding the
* terminating \0. */
char *utf8; /* UTF-8 representation (null-terminated) */
Py_ssize_t wstr_length; /* Number of code points in wstr, possible
* surrogates count as two code points. */
} PyCompactUnicodeObject;
/* Strings allocated through PyUnicode_FromUnicode(NULL, len) use the
PyUnicodeObject structure. The actual string data is initially in the wstr
block, and copied into the data block using _PyUnicode_Ready. */
typedef struct {
PyCompactUnicodeObject _base;
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data; /* Canonical, smallest-form Unicode buffer */
} PyUnicodeObject;
/* This dictionary holds all interned unicode strings. Note that references
to strings in this dictionary are *not* counted in the string's ob_refcnt.
When the interned string reaches a refcnt of 0 the string deallocation
function will delete the reference from this dictionary.
Another way to look at this is that to say that the actual reference
count of a string is: s->ob_refcnt + (s->state ? 2 : 0)
*/
static PyObject *interned = NULL;
void
PyUnicode_InternInPlace(PyObject **p)
{
PyObject *s = *p;
PyObject *t;
#ifdef Py_DEBUG
assert(s != NULL);
assert(_PyUnicode_CHECK(s));
#else
if (s == NULL || !PyUnicode_Check(s))
return;
#endif
/* If it's a subclass, we don't really know what putting
it in the interned dict might do. */
if (!PyUnicode_CheckExact(s))
return;
if (PyUnicode_CHECK_INTERNED(s))
return;
if (interned == NULL) {
interned = PyDict_New();
if (interned == NULL) {
PyErr_Clear(); /* Don't leave an exception */
return;
}
}
Py_ALLOW_RECURSION
t = PyDict_SetDefault(interned, s, s);
Py_END_ALLOW_RECURSION
if (t == NULL) {
PyErr_Clear();
return;
}
if (t != s) {
Py_INCREF(t);
Py_SETREF(*p, t);
return;
}
/* The two references in interned are not counted by refcnt.
The deallocator will take care of this */
Py_REFCNT(s) -= 2;
_PyUnicode_STATE(s).interned = SSTATE_INTERNED_MORTAL;
}
>>> a = 'abc'
>>> b = 'ab' + 'c'
>>> id(a), id(b), a is b
(2752416949872, 2752416949872, True)
The above is the detailed content of Python built-in type str source code analysis. For more information, please follow other related articles on the PHP Chinese website!
Statement of this Website
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn
The key to dealing with API authentication is to understand and use the authentication method correctly. 1. APIKey is the simplest authentication method, usually placed in the request header or URL parameters; 2. BasicAuth uses username and password for Base64 encoding transmission, which is suitable for internal systems; 3. OAuth2 needs to obtain the token first through client_id and client_secret, and then bring the BearerToken in the request header; 4. In order to deal with the token expiration, the token management class can be encapsulated and automatically refreshed the token; in short, selecting the appropriate method according to the document and safely storing the key information is the key.
To test the API, you need to use Python's Requests library. The steps are to install the library, send requests, verify responses, set timeouts and retry. First, install the library through pipinstallrequests; then use requests.get() or requests.post() and other methods to send GET or POST requests; then check response.status_code and response.json() to ensure that the return result is in compliance with expectations; finally, add timeout parameters to set the timeout time, and combine the retrying library to achieve automatic retry to enhance stability.
To create modern and efficient APIs using Python, FastAPI is recommended; it is based on standard Python type prompts and can automatically generate documents, with excellent performance. After installing FastAPI and ASGI server uvicorn, you can write interface code. By defining routes, writing processing functions, and returning data, APIs can be quickly built. FastAPI supports a variety of HTTP methods and provides automatically generated SwaggerUI and ReDoc documentation systems. URL parameters can be captured through path definition, while query parameters can be implemented by setting default values ??for function parameters. The rational use of Pydantic models can help improve development efficiency and accuracy.
In Python, variables defined inside a function are local variables and are only valid within the function; externally defined are global variables that can be read anywhere. 1. Local variables are destroyed as the function is executed; 2. The function can access global variables but cannot be modified directly, so the global keyword is required; 3. If you want to modify outer function variables in nested functions, you need to use the nonlocal keyword; 4. Variables with the same name do not affect each other in different scopes; 5. Global must be declared when modifying global variables, otherwise UnboundLocalError error will be raised. Understanding these rules helps avoid bugs and write more reliable functions.
How to efficiently handle large JSON files in Python? 1. Use the ijson library to stream and avoid memory overflow through item-by-item parsing; 2. If it is in JSONLines format, you can read it line by line and process it with json.loads(); 3. Or split the large file into small pieces and then process it separately. These methods effectively solve the memory limitation problem and are suitable for different scenarios.
Python default parameters are evaluated and fixed values ??when the function is defined, which can cause unexpected problems. Using variable objects such as lists as default parameters will retain modifications, and it is recommended to use None instead; the default parameter scope is the environment variable when defined, and subsequent variable changes will not affect their value; avoid relying on default parameters to save state, and class encapsulation state should be used to ensure function consistency.
In Python, the method of traversing tuples with for loops includes directly iterating over elements, getting indexes and elements at the same time, and processing nested tuples. 1. Use the for loop directly to access each element in sequence without managing the index; 2. Use enumerate() to get the index and value at the same time. The default index is 0, and the start parameter can also be specified; 3. Nested tuples can be unpacked in the loop, but it is necessary to ensure that the subtuple structure is consistent, otherwise an unpacking error will be raised; in addition, the tuple is immutable and the content cannot be modified in the loop. Unwanted values can be ignored by \_. It is recommended to check whether the tuple is empty before traversing to avoid errors.
Python implements asynchronous API calls with async/await with aiohttp. Use async to define coroutine functions and execute them through asyncio.run driver, for example: asyncdeffetch_data(): awaitasyncio.sleep(1); initiate asynchronous HTTP requests through aiohttp, and use asyncwith to create ClientSession and await response result; use asyncio.gather to package the task list; precautions include: avoiding blocking operations, not mixing synchronization code, and Jupyter needs to handle event loops specially. Master eventl