


Snowpark: Apprentissage automatique dans la database avec flocon de neige
L'apprentissage automatique traditionnel implique souvent de déplacer des ensembles de données massifs des bases de données aux environnements de formation de modèle. Ceci est de plus en plus inefficace avec les grands ensembles de données d'aujourd'hui. SnowFlake Snowpark aborde cela en permettant un traitement en database. Snowpark fournit des bibliothèques et des temps d'exécution pour exécuter du code (Python, Java, Scala) directement dans le nuage de Snowflake, minimisant le mouvement des données et améliorant la sécurité.
Pourquoi choisir Snowpark?
Snowpark offre plusieurs avantages clés:
- Traitement en database: Manipuler et analyser les données de flocon de neige en utilisant votre langage préféré sans transfert de données.
- Amélioration des performances: Tirez parti de l'architecture évolutive de Snowflake pour un traitement efficace.
- Réduction des co?ts: Minimiser les frais généraux de gestion des infrastructures.
- Outils familiers: Intégrer aux outils existants comme Jupyter ou VS Code, et utilisez des bibliothèques familières (Pandas, Scikit-Learn, XgBoost).
Début: un guide étape par étape
Ce tutoriel démontre la construction d'un modèle réglé par hyperparamètre en utilisant des neiges.
-
Configuration de l'environnement virtuel: Créez un environnement conda et installez les bibliothèques nécessaires (
snowflake-snowpark-python,pandas,pyarrow,numpy,matplotlib,seaborn,ipykernel). -
Ingestion de données: Importez des données d'échantillonnage (par exemple, l'ensemble de données des diamants Seaborn) dans une table de flocon de neige. (Remarque: Dans les scénarios du monde réel, vous travaillerez généralement avec les bases de données de flocon de neige existantes.)
-
Création de session Snowpark: établissez une connexion à Snowflake en utilisant vos informations d'identification (nom de compte, nom d'utilisateur, mot de passe) stocké en toute sécurité dans un fichier
config.py(ajouté à.gitignore). -
Chargement des données: Utilisez la session de neige pour accéder et charger les données dans un snowpark dataframe.
Comprendre les données de données de neige
Snowpark DataFrames fonctionne paresseusement, créant une représentation logique des opérations avant de les traduire en requêtes SQL optimisées. Cela contraste avec l'exécution impatient de Pandas, offrant des gains de performances significatifs, en particulier avec les grands ensembles de données.
Quand utiliser des données de données neigeuses:
Utilisez des données de données de neige pour de grands ensembles de données où le transfert de données vers votre machine locale n'est pas pratique. Pour les ensembles de données plus petits, les pandas peuvent être suffisants. La méthode to_pandas() permet la conversion entre les neiges et Pandas DataFrames. La méthode Session.sql() fournit une alternative pour exécuter directement les requêtes SQL.
Snowpark dataframe Transformation Fonctions:
Les fonctions de transformation de Snowpark (importées comme F de snowflake.snowpark.functions) fournissent une interface puissante pour la manipulation des données. Ces fonctions sont utilisées avec des méthodes .select(), .filter() et .with_column().
Analyse des données exploratoires (EDA):
EDA peut être effectué en échantillonnant des données de la fragmentation des données de neige, en les convertissant en un Pandas DataFrame et en utilisant des bibliothèques de visualisation comme Matplotlib et SeaBorn. Alternativement, les requêtes SQL peuvent générer des données pour les visualisations.
Formation du modèle d'apprentissage automatique:
-
Nettoyage des données: Assurer que les types de données sont corrects et gérer tous les besoins de prétraitement (par exemple, les colonnes de renommage, les types de données de casting, le nettoyage des caractéristiques du texte).
-
Prétraitement: Utilisez Snowflake ML
PipelineavecOrdinalEncoderetStandardScalerpour prétraiter les données. Enregistrez le pipeline en utilisantjoblib. -
Formation du modèle: Former un modèle XGBOost (
XGBRegressor) en utilisant les données prétraitées. Divisez les données en ensembles de formation et de test en utilisantrandom_split(). -
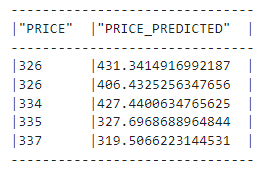
évaluation du modèle: évaluer le modèle à l'aide de mesures comme RMSE (
mean_squared_errordesnowflake.ml.modeling.metrics). -
Tunage hyperparamètre: Utiliser
RandomizedSearchCVpour optimiser les hyperparamètres du modèle. -
économie du modèle: Enregistrez le modèle formé et ses métadonnées vers le registre du modèle de Snowflake en utilisant la classe
Registry. -
Inférence: Effectuez l'inférence sur les nouvelles données en utilisant le modèle enregistré du registre.
Conclusion:
Snowpark fournit un moyen puissant et efficace d'effectuer l'apprentissage automatique dans la catabase. Son évaluation paresseuse, son intégration avec des bibliothèques familières et son registre de modèles en font un outil précieux pour gérer de grands ensembles de données. N'oubliez pas de consulter l'API Snowpark et les guides de développeur ML pour des fonctionnalités et des fonctionnalités plus avancées.












Remarque: Les URL de l'image sont conservées à partir de l'entrée. Le formatage est ajusté pour une meilleure lisibilité et une meilleure écoute. Les détails techniques sont conservés, mais la langue est rendue plus concise et accessible à un public plus large.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
échangez les visages dans n'importe quelle vidéo sans effort grace à notre outil d'échange de visage AI entièrement gratuit?!

Article chaud
Outils chauds

Bloc-notes++7.3.1
éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Kimi K2: le modèle agentique open source le plus puissant
Jul 12, 2025 am 09:16 AM
Kimi K2: le modèle agentique open source le plus puissant
Jul 12, 2025 am 09:16 AM
Rappelez-vous le flot de modèles chinois open source qui a perturbé l'industrie du Genai plus t?t cette année? Alors que Deepseek a fait la majeure partie des titres, Kimi K1.5 était l'un des noms importants de la liste. Et le modèle était assez cool.
 Grok 4 vs Claude 4: Quel est le meilleur?
Jul 12, 2025 am 09:37 AM
Grok 4 vs Claude 4: Quel est le meilleur?
Jul 12, 2025 am 09:37 AM
à la mi-2025, l'AI ?Arme Race? se réchauffe, et Xai et Anthropic ont tous deux publié leurs modèles phares, Grok 4 et Claude 4.
 10 robots humano?des incroyables qui marchent déjà parmi nous aujourd'hui
Jul 16, 2025 am 11:12 AM
10 robots humano?des incroyables qui marchent déjà parmi nous aujourd'hui
Jul 16, 2025 am 11:12 AM
Mais nous n'aurons probablement pas à attendre même 10 ans pour en voir un. En fait, ce qui pourrait être considéré comme la première vague de machines vraiment utiles, de type humain, est déjà là. Les dernières années ont vu un certain nombre de prototypes et de modèles de production sortant de T
 6 taches manus ai peut faire en quelques minutes
Jul 06, 2025 am 09:29 AM
6 taches manus ai peut faire en quelques minutes
Jul 06, 2025 am 09:29 AM
Je suis s?r que vous devez conna?tre l'agent général de l'IA, Manus. Il a été lancé il y a quelques mois, et au cours des mois, ils ont ajouté plusieurs nouvelles fonctionnalités à leur système. Maintenant, vous pouvez générer des vidéos, créer des sites Web et faire beaucoup de MO
 L'ingénierie contextuelle est la & # 039; New & # 039; Ingénierie rapide
Jul 12, 2025 am 09:33 AM
L'ingénierie contextuelle est la & # 039; New & # 039; Ingénierie rapide
Jul 12, 2025 am 09:33 AM
Jusqu'à l'année précédente, l'ingénierie rapide était considérée comme une compétence cruciale pour interagir avec les modèles de langage grand (LLM). Récemment, cependant, les LLM ont considérablement progressé dans leurs capacités de raisonnement et de compréhension. Naturellement, nos attentes
 L'application mobile d'immersité de Leia apporte une profondeur 3D aux photos de tous les jours
Jul 09, 2025 am 11:17 AM
L'application mobile d'immersité de Leia apporte une profondeur 3D aux photos de tous les jours
Jul 09, 2025 am 11:17 AM
Construit sur le moteur de profondeur neuronale propriétaire de Leia, l'application traite des images fixes et ajoute de la profondeur naturelle avec un mouvement simulé - comme les casseroles, les zooms et les effets de parallaxe - pour créer de courts bobines vidéo qui donnent l'impression de pénétrer dans le SCE
 Quels sont les 7 types d'agents d'IA?
Jul 11, 2025 am 11:08 AM
Quels sont les 7 types d'agents d'IA?
Jul 11, 2025 am 11:08 AM
Imaginez quelque chose de sophistiqué, comme un moteur d'IA prêt à donner des commentaires détaillés sur une nouvelle collection de vêtements de Milan, ou une analyse de marché automatique pour une entreprise opérant dans le monde entier, ou des systèmes intelligents gérant une grande flotte de véhicules.
 Ces modèles d'IA n'ont pas appris la langue, ils ont appris la stratégie
Jul 09, 2025 am 11:16 AM
Ces modèles d'IA n'ont pas appris la langue, ils ont appris la stratégie
Jul 09, 2025 am 11:16 AM
Une nouvelle étude de chercheurs du King’s College de Londres et de l’Université d’Oxford partage les résultats de ce qui s'est passé lorsque Openai, Google et Anthropic ont été jetés ensemble dans un concours fardé basé sur le dilemme du prisonnier itéré. Ce n'était pas
