
 Périphériques technologiques
IA
Coca: les légendes contrastives sont des modèles de fondation de texte d'image expliqués visuellement
Périphériques technologiques
IA
Coca: les légendes contrastives sont des modèles de fondation de texte d'image expliqués visuellement
Coca: les légendes contrastives sont des modèles de fondation de texte d'image expliqués visuellement
Mar 10, 2025 am 11:17 AM
Ce didacticiel communautaire DataCamp, édité pour plus de clarté et de précision, explore les modèles de fondation de texte d'image, en se concentrant sur le modèle innovant de souscription contrastive (COCA). Coca combine uniquement les objectifs d'apprentissage contrastives et génératifs, intégrant les forces de modèles comme Clip et SimVlm dans une seule architecture.

Modèles de fondation: une plongée profonde
Les modèles de fondation, pré-formés sur des ensembles de données massifs, sont adaptables à diverses taches en aval. Alors que la PNL a vu une surtension dans les modèles de fondation (GPT, Bert), les modèles de vision et de vision sont toujours en évolution. La recherche a exploré trois approches primaires: les modèles à encodeur unique, les deux codes à double texte avec une perte contrastive et les modèles de coder avec des objectifs génératifs. Chaque approche a des limites.
Termes clés:
- Modèles de fondation: Modèles pré-formés adaptables pour diverses applications.
- Perte contrastive: Une fonction de perte comparant des paires d'entrée similaires et différentes.
- Interaction intermodale: Interaction entre différents types de données (par exemple, image et texte).
- Architecture d'encodeur-décodeur: Une entrée de traitement du réseau neuronal et générer une sortie.
- Apprentissage zéro-shot: Prédire sur les classes de données invisibles.
- Clip: Un modèle de pré-formation d'image linguistique contrasté.
- simvlm: un modèle de langage visuel simple.
Comparaisons de modèle:
- Modèles d'encodeur uniques: Exceller dans les taches de vision mais lutter contre les taches en langue visuelle dues à la dépendance aux annotations humaines.
- Modèles à double encodeur de texte d'image (clip, aligner): Excellent pour la classification zéro et la récupération d'image, mais limité dans les taches nécessitant des représentations de texte d'image fusionnées (par exemple, réponse à la question visuelle).
- Modèles génératifs (SIMVLM): Utilisez une interaction intermodale pour la représentation de texte d'image conjointe, adaptée à VQA et sous-titrage de l'image.
Coca: combler l'écart
Coca vise à unifier les forces des approches contrastives et génératives. Il utilise une perte contrastive pour aligner les représentations d'image et de texte et un objectif génératif (perte de sous-titrage) pour créer une représentation conjointe.
Architecture Coca:
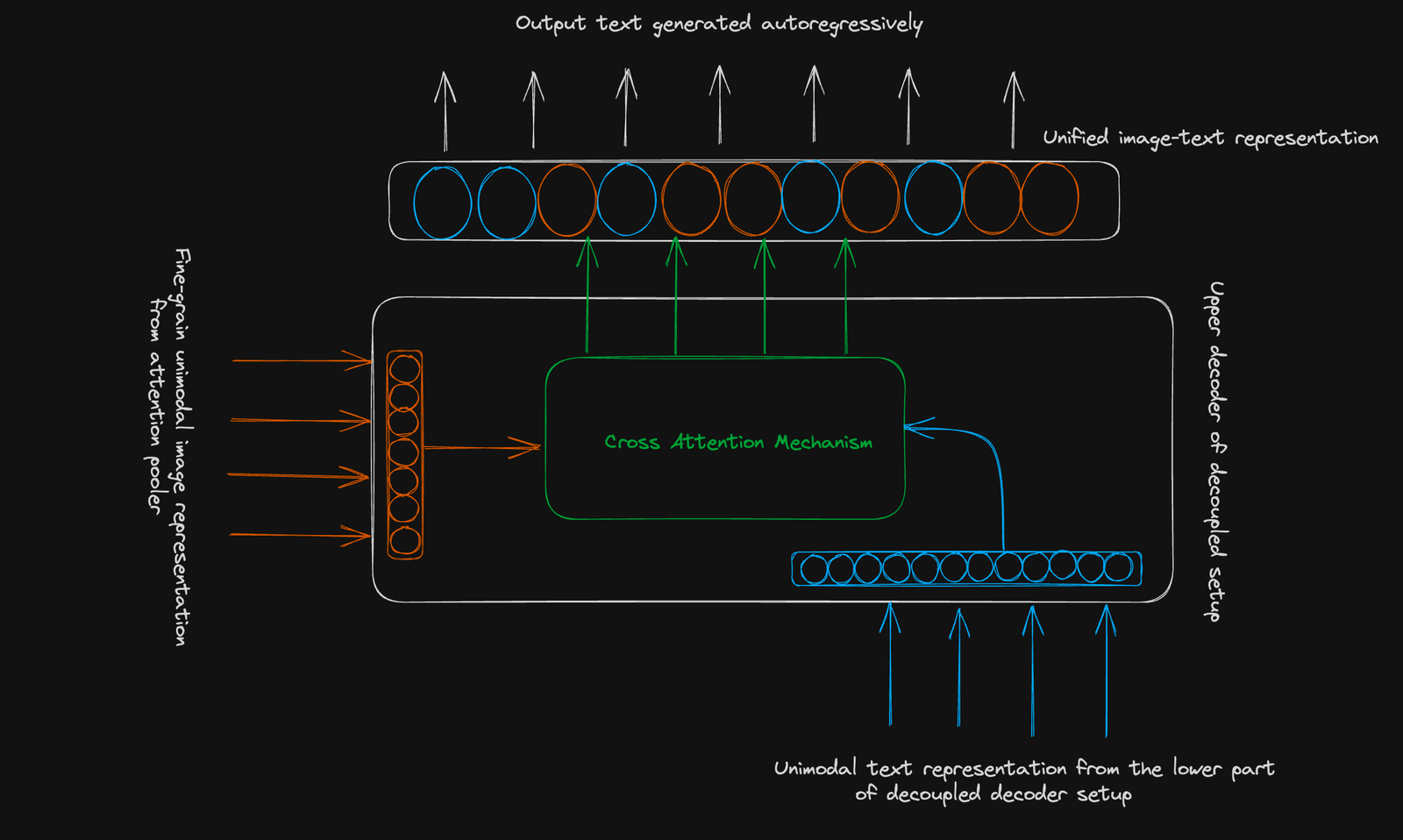
COCA utilise une structure de coder standard. Son innovation réside dans un décodeur découplé :
- Décodeur inférieur: génère une représentation de texte unimodale pour l'apprentissage contrastif (en utilisant un jeton [CLS]).
- Décodeur supérieur: génère une représentation de texte d'image multimodale pour l'apprentissage génératif. Les deux décodeurs utilisent le masquage causal.
Objectif contrastif: apprend à cluster des paires de texte d'image liées et à séparer les paires non liées dans un espace vectoriel partagé. Une seule image regroupée est utilisée.
Objectif génératif: utilise une représentation d'image à grain fin (séquence 256 dimension) et l'attention croisée-modale pour prédire le texte de manière autorégressive.

Conclusion:
COCA représente une progression significative dans les modèles de fondation de texte d'image. Son approche combinée améliore les performances dans diverses taches, offrant un outil polyvalent pour les applications en aval. Pour approfondir votre compréhension des concepts avancés d'apprentissage en profondeur, considérez le cours avancé de Deep Learning with Keras de DataCamp.
Lire plus approfondie:
- Apprentissage des modèles visuels transférables de la supervision du langage naturel
- Pré-formation de texte d'image avec des légendes contrastives
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
échangez les visages dans n'importe quelle vidéo sans effort grace à notre outil d'échange de visage AI entièrement gratuit?!

Article chaud
Outils chauds

Bloc-notes++7.3.1
éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Kimi K2: le modèle agentique open source le plus puissant
Jul 12, 2025 am 09:16 AM
Kimi K2: le modèle agentique open source le plus puissant
Jul 12, 2025 am 09:16 AM
Rappelez-vous le flot de modèles chinois open source qui a perturbé l'industrie du Genai plus t?t cette année? Alors que Deepseek a fait la majeure partie des titres, Kimi K1.5 était l'un des noms importants de la liste. Et le modèle était assez cool.
 Grok 4 vs Claude 4: Quel est le meilleur?
Jul 12, 2025 am 09:37 AM
Grok 4 vs Claude 4: Quel est le meilleur?
Jul 12, 2025 am 09:37 AM
à la mi-2025, l'AI ?Arme Race? se réchauffe, et Xai et Anthropic ont tous deux publié leurs modèles phares, Grok 4 et Claude 4.
 10 robots humano?des incroyables qui marchent déjà parmi nous aujourd'hui
Jul 16, 2025 am 11:12 AM
10 robots humano?des incroyables qui marchent déjà parmi nous aujourd'hui
Jul 16, 2025 am 11:12 AM
Mais nous n'aurons probablement pas à attendre même 10 ans pour en voir un. En fait, ce qui pourrait être considéré comme la première vague de machines vraiment utiles, de type humain, est déjà là. Les dernières années ont vu un certain nombre de prototypes et de modèles de production sortant de T
 L'application mobile d'immersité de Leia apporte une profondeur 3D aux photos de tous les jours
Jul 09, 2025 am 11:17 AM
L'application mobile d'immersité de Leia apporte une profondeur 3D aux photos de tous les jours
Jul 09, 2025 am 11:17 AM
Construit sur le moteur de profondeur neuronale propriétaire de Leia, l'application traite des images fixes et ajoute de la profondeur naturelle avec un mouvement simulé - comme les casseroles, les zooms et les effets de parallaxe - pour créer de courts bobines vidéo qui donnent l'impression de pénétrer dans le SCE
 L'ingénierie contextuelle est la & # 039; New & # 039; Ingénierie rapide
Jul 12, 2025 am 09:33 AM
L'ingénierie contextuelle est la & # 039; New & # 039; Ingénierie rapide
Jul 12, 2025 am 09:33 AM
Jusqu'à l'année précédente, l'ingénierie rapide était considérée comme une compétence cruciale pour interagir avec les modèles de langage grand (LLM). Récemment, cependant, les LLM ont considérablement progressé dans leurs capacités de raisonnement et de compréhension. Naturellement, nos attentes
 Quels sont les 7 types d'agents d'IA?
Jul 11, 2025 am 11:08 AM
Quels sont les 7 types d'agents d'IA?
Jul 11, 2025 am 11:08 AM
Imaginez quelque chose de sophistiqué, comme un moteur d'IA prêt à donner des commentaires détaillés sur une nouvelle collection de vêtements de Milan, ou une analyse de marché automatique pour une entreprise opérant dans le monde entier, ou des systèmes intelligents gérant une grande flotte de véhicules.
 Ces modèles d'IA n'ont pas appris la langue, ils ont appris la stratégie
Jul 09, 2025 am 11:16 AM
Ces modèles d'IA n'ont pas appris la langue, ils ont appris la stratégie
Jul 09, 2025 am 11:16 AM
Une nouvelle étude de chercheurs du King’s College de Londres et de l’Université d’Oxford partage les résultats de ce qui s'est passé lorsque Openai, Google et Anthropic ont été jetés ensemble dans un concours fardé basé sur le dilemme du prisonnier itéré. Ce n'était pas
 Crise de commandement dissimulé: les chercheurs jeu aiment être publiés
Jul 13, 2025 am 11:08 AM
Crise de commandement dissimulé: les chercheurs jeu aiment être publiés
Jul 13, 2025 am 11:08 AM
Les scientifiques ont découvert une méthode intelligente mais alarmante pour contourner le système. Juillet 2025 a marqué la découverte d'une stratégie élaborée où les chercheurs ont inséré des instructions invisibles dans leurs soumissions académiques - ces directives secrètes étaient la queue
