
 Périphériques technologiques
IA
Claude 4 vs GPT-4O VS GEMINI 2.5 Pro: Trouvez la meilleure IA pour le codage
Périphériques technologiques
IA
Claude 4 vs GPT-4O VS GEMINI 2.5 Pro: Trouvez la meilleure IA pour le codage
Claude 4 vs GPT-4O VS GEMINI 2.5 Pro: Trouvez la meilleure IA pour le codage
May 26, 2025 am 09:40 AM
En 2025, les développeurs ne demandent plus comment utiliser les outils d'IA pour le codage, ils demandent quelle est la meilleure IA pour la génération de code. Avec l'accès à tant de modèles les plus performants comme Claude 4 d'Anthropic, le GPT-4O d'Openai et le Gemini 2.5 Pro de Google, il y a une concurrence étroite dans la race AI et beaucoup de confusion dans nos esprits. Alors que le domaine AI continue d'évoluer, il est nécessaire d'évaluer comment ces modèles fonctionnent en matière de génération de code. Dans cet article, nous comparerons les capacités de programmation et les performances de Claude 4 Sonnet vs GPT-4O vs Gemini 2.5 Pro, pour savoir quel est le meilleur modèle de codage d'IA.
Table des matières
- évaluation du modèle: Claude 4 vs GPT-4O vs Gemini 2.5 Pro
- Présentation du modèle
- Comparaison des prix
- Comparaison de référence
- Analyse globale
- Claude 4 vs GPT-4O VS GEMINI 2.5 Pro: Capacités de codage
- Tache 1: Concevez des cartes à jouer avec HTML, CSS et JS
- Tache 2: construire un jeu
- Tache 3: Meilleur temps pour acheter et vendre des actions
- Verdict final: analyse globale
- Conclusion
évaluation du modèle: Claude 4 vs GPT-4O vs Gemini 2.5 Pro
Pour trouver le meilleur modèle de codage AI en 2025, nous évaluerons d'abord Claude 4 Sonnet, GPT-4O et Gemini 2.5 Pro, en fonction de leur architecture, de leur fenêtre de contexte, de leur prix et de leurs scores de référence.
Présentation du modèle
Chacun de ces modèles est accessible via les services cloud et a des capacités multimodales à des degrés divers. Dans cette section, nous explorerons certaines des principales caractéristiques des 3 modèles et comparerons ce qu'ils offrent.
| Fonctionnalité | Claude 4 | GPT-4O | Gemini 2.5 Pro |
| Open source | Non | Non | Non |
| Date de sortie | 22 mai 2025 | Mai 2024 | 6 mai 2025 |
| Fenêtre de contexte | 200K | 128K | 1m |
| Fournisseurs d'API | API anthropique, ombrage AWS, Google Vertex | API Openai, Azure Openai | Google Vertex AI, Google AI Studio |
| Types d'entrée pris en charge | Texte, images | Texte, images, audio, vidéo | Texte, images, audio, vidéo |
Comparaison des prix
à l'ère moderne de l'IA, chacun de nous utilise ces modèles dans une certaine mesure. Ainsi, le prix du modèle est l'une des choses importantes pour les équipes tout en créant des applications à grande échelle, et Claude 4 Opus se distingue comme la plus chère pour les entrées et les sorties.
| Modèle | Prix ??d'entrée (par million de jetons) | Prix ??de production (par million de jetons) |
| Claude 4 | 15,00 $ (OPU) 3,00 $ (Sonnet) |
75,00 $ (OPU) 15,00 $ (Sonnet) |
| GPT-4O | 5,00 $ | 20,00 $ |
| Gemini 2.5 Pro | 1,25 $ (≤ 200K), 2,50 $ (> 200k) |
10,00 $ (≤ 200K), 15,00 $ (> 200k) |
Comparaison de référence
Benchmark illustre les capacités des modèles comme le codage et le raisonnement. Le résultat reflète les performances de son modèle sur divers domaines disponibles sur les données sur le codage agentique, les mathématiques, le raisonnement et l'utilisation des outils.
| Référence | Claude 4 Opus | Claude 4 Sonnet | GPT-4O | Gemini 2.5 Pro |
| Humaneval (Code Gen) | Pas disponible | Pas disponible | 74,8% | 75,6% |
| GPQA (raisonnement des dipl?mes) | 83,3% | 83,8% | 83,3% | 83,0% |
| MMLU (Connaissance mondiale) | 88,8% | 86,5% | 88,7% | 88,6% |
| Aime 2025 (mathématiques) | 90,0% | 85,0% | 88,9% | 83,0% |
| Swe-Bench (codage agentique) | 72,5% | 72,7% | 69,1% | 63,2% |
| Tau-banc (utilisation des outils) | 81,4% | 80,5% | 70,4% | Pas disponible |
| Banc de terminal (codage) | 43,2% | 35,5% | 30,2% | 25,3% |
| MMMU (raisonnement visuel) | 76,5% | 74,4% | 82,9% | 79,6% |
En cela, Claude 4 excelle généralement dans le codage, GPT-4O dans le raisonnement et Gemini 2.5 Pro offre des performances solides et équilibrées dans différentes modalités. Pour plus d'informations, veuillez visiter ici .
Analyse globale
Voici ce que nous avons appris sur ces modèles de cl?ture avancés, sur la base des points de comparaison ci-dessus:
- Nous avons constaté que Claude 4 excelle dans le codage, les mathématiques et l'utilisation d'outils, mais c'est aussi le plus cher.
- GPT-4O excelle au raisonnement et le support multimodal, gérant différents formats d'entrée, ce qui en fait un choix idéal pour des assistants plus avancés et complexes.
- Pendant ce temps, Gemini 2.5 Pro offre une performance solide et équilibrée avec la plus grande fenêtre de contexte et la tarification la plus rentable.
Claude 4 vs GPT-4O VS GEMINI 2.5 Pro: Capacités de codage
Nous allons maintenant comparer les capacités d'écriture de code de Claude 4, GPT-4O et Gemini 2.5 Pro. Pour cela, nous allons donner la même invite aux trois modèles et évaluer leurs réponses sur les mesures suivantes:
- Efficacité
- Lisibilité
- Commentaire et documentation
- Gestion des erreurs
Tache 1: Concevez des cartes à jouer avec HTML, CSS et JS
Invite: ? Créez une page Web interactive qui affiche une collection de cartes flash superstar de la WWE à l'aide de HTML, CSS et JavaScript. Chaque carte doit représenter un lutteur de la WWE et doit inclure un c?té avant et arrière. Sur le devant, afficher le nom et l'image du lutteur. Le dos, affichez des statistiques supplémentaires telles que leur déménagement final, la marque et les titres de championnat. Le flashcards devrait avoir une animation de flip lors de la fin de la marque.
De plus, ajoutez des commandes interactives pour rendre la page dynamique: un bouton qui mélange les cartes, et une autre qui montre une carte aléatoire du jeu. La disposition doit être visuellement attrayante et réactive pour différentes tailles d'écran. Points bonus si vous incluez des effets sonores comme la musique d'entrée lorsqu'une carte est retournée.
Caractéristiques clés à implémenter:
- Front de carte: Image du nom du lutteur
- Back of Card: Statistiques (par exemple, finisseur, marque, titres)
- Flip Animation à l'aide de CSS ou JS
- Le bouton ?remanier? pour réorganiser au hasard les cartes
- Bouton "Afficher la superstar aléatoire"
- Conception réactive. "
Réponse de Claude 4:
Réponse de GPT-4O:
Réponse de Gemini 2.5 Pro:
Analyse comparative
Dans la première tache, Claude 4 a donné l'expérience la plus interactive avec les visuels les plus dynamiques. Il a également ajouté un effet sonore en cliquant sur la carte. GPT-4O a donné une disposition de thème noir avec des transitions lisses et des boutons entièrement fonctionnels, mais manquait de fonctionnalité audio. Pendant ce temps, Gemini 2.5 Pro a donné la disposition séquentielle la plus simple et la plus basique sans animation ni son. De plus, la fonction de carte aléatoire de celle-ci n'a pas réussi à afficher correctement le visage de la carte. Dans l'ensemble, Claude prend les devants ici, suivis par GPT-4O, puis Gemini.
Tache 2: construire un jeu
Invite: ? Le jeu de stratégie de sorts est un jeu de bataille au tour par tour construit avec Pygame, où deux mages rivalisent en lan?ant des sorts à partir de leurs livres de sorts. Chaque joueur commence par 100 ch et 100 mana et se prend à tour de r?le Indicateurs de recharge. Les joueurs peuvent s'affronter contre un autre humain ou un adversaire de l'IA, visant à réduire les HP de leur rival à zéro par des décisions tactiques.
Caractéristiques clés:
- Gameplay au tour par tour avec deux mages (PVP ou PVAI)
- 100 ch et 100 mana par joueur
- Spellbook with divers sorts: dommages, guérison, boucliers, étourdissements, recharge de mana
- Les co?ts de mana et les temps de recharge pour chaque sort pour encourager le jeu stratégique
- éléments d'interface utilisateur visuels: barres de santé / mana, indicateurs de recharge, ic?nes de sorts
- Adversaire de l'IA avec une prise de décision tactique simple
- Contr?les pilotés par souris avec raccourcis clavier en option
- Messagerie claire dans le jeu montrant des actions et des effets ?
Réponse de Claude 4:
Réponse de GPT-4O:
Réponse de Gemini 2.5 Pro:
Analyse comparative
Dans la deuxième tache, dans l'ensemble, aucun des modèles n'a fourni des graphiques appropriés. Chacun affichait un écran noir avec une interface minimale. Cependant, Claude 4 a offert le contr?le le plus fonctionnel et le plus fluide sur le jeu, avec un large éventail d'attaques, de défense et d'autres gameplay stratégiques. Le GPT-4O, en revanche, a souffert de problèmes de performance, tels que la retard, et une taille de fenêtre petite et concise. Même Gemini 2.5 Pro n'a pas réussi ici, car son code n'a pas réussi et a donné quelques erreurs. Dans l'ensemble, encore une fois, Claude prend les devants ici, suivis par GPT-4O, puis Gemini 2.5 Pro.
Tache 3: Meilleur temps pour acheter et vendre des actions
Invite: ? On vous donne des prix du tableau où les prix [i] sont le prix d'un stock donné le premier jour.
Trouvez le bénéfice maximum que vous pouvez réaliser. Vous pouvez effectuer au plus deux transactions.
Remarque: vous ne pouvez pas vous engager simultanément dans plusieurs transactions (c'est-à-dire que vous devez vendre l'action avant d'acheter à nouveau).
Exemple:
Entrée: Prix = [3,3,5,0,0,3,1,4]
Sortie: 6
Explication: Achetez le jour 4 (prix = 0) et vendez le jour 6 (prix = 3), profit = 3-0 = 3. Ensuite, achetez le jour 7 (prix = 1) et vendez le jour 8 (prix = 4), profit = 4-1 = 3. ?
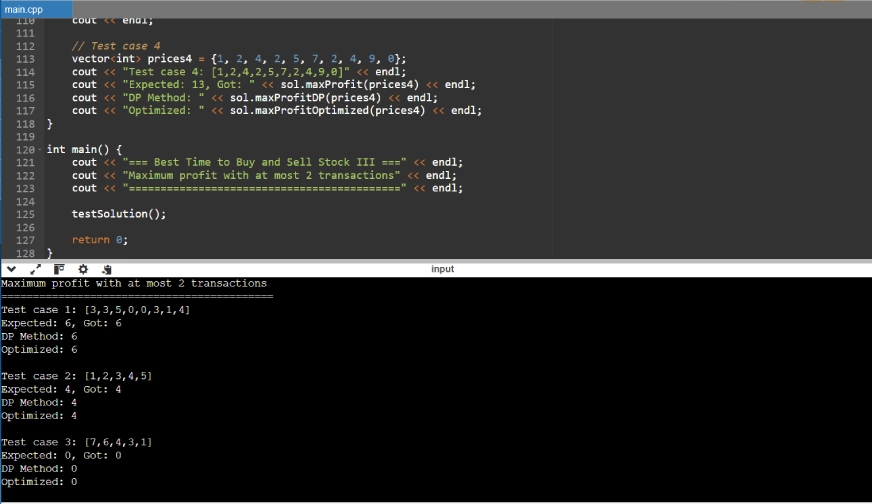
Réponse de Claude 4:
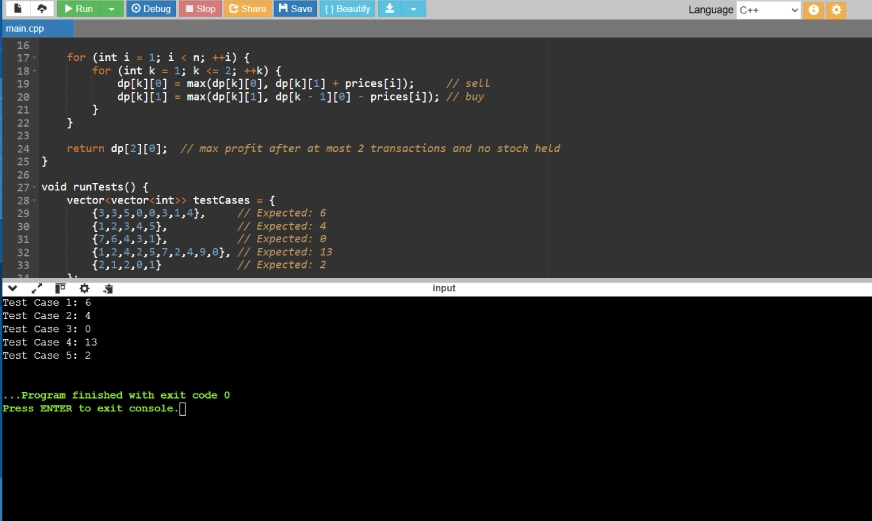
Réponse de GPT-4O:
Réponse de Gemini 2.5 Pro:
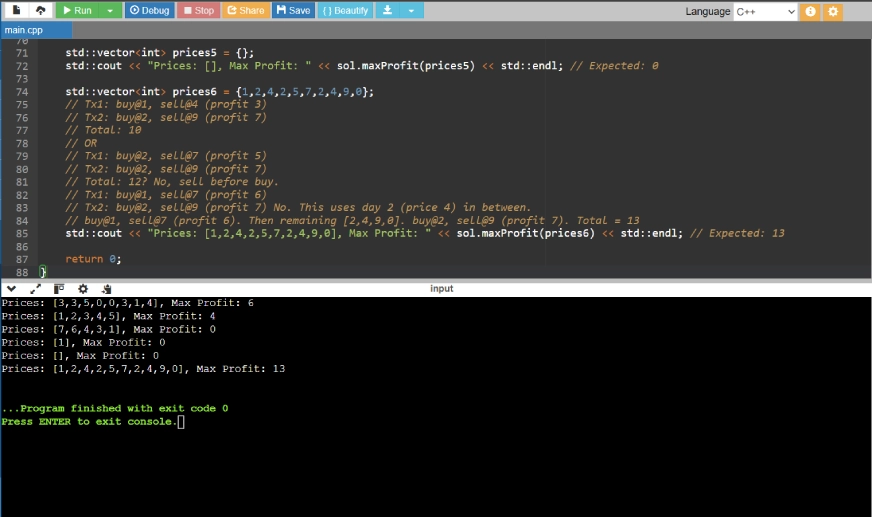
Analyse comparative
Dans la troisième et dernière tache, les modèles ont d? résoudre le problème en utilisant la programmation dynamique . Un Mong les trois, GPT-4O, a offert la solution la plus pratique et la plus approchée, en utilisant une programmation dynamique 2D propre avec une initialisation s?re, et inclut également les cas de test D. Bien que Claude 4 fournisse D une approche plus détaillée et éducative, elle est plus verbeuse. Pendant ce temps, Gemini 2.5 Pro a donné une méthode concise, mais utilise l'initialisation D int_min, qui est une approche risquée. Ainsi, dans cette tache, GPT-4O prend les devants , suivis de Claude 4, puis Gemini 2.5 Pro.
Verdict final: analyse globale
Voici un résumé comparatif de la fa?on dont chaque modèle a fonctionné dans les taches ci-dessus.
| Tache | Claude 4 | GPT-4O | Gemini 2.5 Pro | Gagnant |
| Tache 1 (UI de carte) | Le plus interactif avec les animations et les effets sonores | Thème sombre lisse avec boutons fonctionnels, pas de son | Disposition séquentielle de base, problème de face de la carte, pas d'animation / son | Claude 4 |
| Tache 2 (contr?le du jeu) | Commandes lisses, options de stratégie larges, jeu le plus fonctionnel | Utilisable mais laggy, petite fenêtre | échec de l'exécution, les erreurs d'interface | Claude 4 |
| Tache 3 (programmation dynamique) | Verbeux mais éducatif, bon pour l'apprentissage | Solution DP propre et s?re avec des cas de test, le plus pratique | Concis mais dangereux (utilise int_min), manque de robustesse | GPT-4O |
Pour vérifier la version complète de tous les fichiers de code, veuillez visiter ici .
Conclusion
Maintenant, grace à cette comparaison complète de trois taches diverses, nous avons observé que Claude 4 se démarque avec ses capacités de conception d'interface utilisateur interactives et sa logique stable dans la programmation modulaire, ce qui en fait le plus performant dans son ensemble. Tandis que GPT-4O suit de près avec son codage propre et pratique, et excelle dans la résolution de problèmes algorithmiques. Pendant ce temps, Gemini 2.5 Pro manque dans la conception et la stabilité de l'interface utilisateur dans l'exécution de toutes les taches. Mais ces observations sont complètement basées sur la comparaison ci-dessus, tandis que chaque modèle a des forces uniques, et le choix du modèle dépend complètement du problème que nous essayons de résoudre.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
échangez les visages dans n'importe quelle vidéo sans effort grace à notre outil d'échange de visage AI entièrement gratuit?!

Article chaud
Outils chauds

Bloc-notes++7.3.1
éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Kimi K2: le modèle agentique open source le plus puissant
Jul 12, 2025 am 09:16 AM
Kimi K2: le modèle agentique open source le plus puissant
Jul 12, 2025 am 09:16 AM
Rappelez-vous le flot de modèles chinois open source qui a perturbé l'industrie du Genai plus t?t cette année? Alors que Deepseek a fait la majeure partie des titres, Kimi K1.5 était l'un des noms importants de la liste. Et le modèle était assez cool.
 Grok 4 vs Claude 4: Quel est le meilleur?
Jul 12, 2025 am 09:37 AM
Grok 4 vs Claude 4: Quel est le meilleur?
Jul 12, 2025 am 09:37 AM
à la mi-2025, l'AI ?Arme Race? se réchauffe, et Xai et Anthropic ont tous deux publié leurs modèles phares, Grok 4 et Claude 4.
 10 robots humano?des incroyables qui marchent déjà parmi nous aujourd'hui
Jul 16, 2025 am 11:12 AM
10 robots humano?des incroyables qui marchent déjà parmi nous aujourd'hui
Jul 16, 2025 am 11:12 AM
Mais nous n'aurons probablement pas à attendre même 10 ans pour en voir un. En fait, ce qui pourrait être considéré comme la première vague de machines vraiment utiles, de type humain, est déjà là. Les dernières années ont vu un certain nombre de prototypes et de modèles de production sortant de T
 L'ingénierie contextuelle est la & # 039; New & # 039; Ingénierie rapide
Jul 12, 2025 am 09:33 AM
L'ingénierie contextuelle est la & # 039; New & # 039; Ingénierie rapide
Jul 12, 2025 am 09:33 AM
Jusqu'à l'année précédente, l'ingénierie rapide était considérée comme une compétence cruciale pour interagir avec les modèles de langage grand (LLM). Récemment, cependant, les LLM ont considérablement progressé dans leurs capacités de raisonnement et de compréhension. Naturellement, nos attentes
 L'application mobile d'immersité de Leia apporte une profondeur 3D aux photos de tous les jours
Jul 09, 2025 am 11:17 AM
L'application mobile d'immersité de Leia apporte une profondeur 3D aux photos de tous les jours
Jul 09, 2025 am 11:17 AM
Construit sur le moteur de profondeur neuronale propriétaire de Leia, l'application traite des images fixes et ajoute de la profondeur naturelle avec un mouvement simulé - comme les casseroles, les zooms et les effets de parallaxe - pour créer de courts bobines vidéo qui donnent l'impression de pénétrer dans le SCE
 Quels sont les 7 types d'agents d'IA?
Jul 11, 2025 am 11:08 AM
Quels sont les 7 types d'agents d'IA?
Jul 11, 2025 am 11:08 AM
Imaginez quelque chose de sophistiqué, comme un moteur d'IA prêt à donner des commentaires détaillés sur une nouvelle collection de vêtements de Milan, ou une analyse de marché automatique pour une entreprise opérant dans le monde entier, ou des systèmes intelligents gérant une grande flotte de véhicules.
 Ces modèles d'IA n'ont pas appris la langue, ils ont appris la stratégie
Jul 09, 2025 am 11:16 AM
Ces modèles d'IA n'ont pas appris la langue, ils ont appris la stratégie
Jul 09, 2025 am 11:16 AM
Une nouvelle étude de chercheurs du King’s College de Londres et de l’Université d’Oxford partage les résultats de ce qui s'est passé lorsque Openai, Google et Anthropic ont été jetés ensemble dans un concours fardé basé sur le dilemme du prisonnier itéré. Ce n'était pas
 Crise de commandement dissimulé: les chercheurs jeu aiment être publiés
Jul 13, 2025 am 11:08 AM
Crise de commandement dissimulé: les chercheurs jeu aiment être publiés
Jul 13, 2025 am 11:08 AM
Les scientifiques ont découvert une méthode intelligente mais alarmante pour contourner le système. Juillet 2025 a marqué la découverte d'une stratégie élaborée où les chercheurs ont inséré des instructions invisibles dans leurs soumissions académiques - ces directives secrètes étaient la queue
