
 pembangunan bahagian belakang
Tutorial Python
[Python-CVImage Segmentation : Canny Edges, Watershed dan Kaedah K-Means
pembangunan bahagian belakang
Tutorial Python
[Python-CVImage Segmentation : Canny Edges, Watershed dan Kaedah K-Means
[Python-CVImage Segmentation : Canny Edges, Watershed dan Kaedah K-Means
Dec 11, 2024 am 05:33 AM
Segmentasi ialah teknik asas dalam analisis imej yang membolehkan kita membahagikan imej kepada bahagian yang bermakna berdasarkan objek, bentuk atau warna. Ia memainkan peranan penting dalam aplikasi seperti pengesanan objek, penglihatan komputer, dan juga manipulasi imej artistik. Tetapi bagaimana kita boleh mencapai segmentasi dengan berkesan? Nasib baik, OpenCV (cv2) menyediakan beberapa kaedah yang mesra pengguna dan berkuasa untuk pembahagian.
Dalam tutorial ini, kami akan meneroka tiga teknik pembahagian yang popular:
- Pengesanan Tepi Canny – sesuai untuk menggariskan objek.
- Algoritma Tadahan Air – bagus untuk mengasingkan kawasan bertindih.
- K-Means Color Segmentation – sesuai untuk mengelompokkan warna yang serupa dalam imej.
Untuk menjadikan tutorial ini menarik dan praktikal, kami akan menggunakan imej satelit dan udara dari Osaka, Jepun, memfokuskan pada busut kubur kofun purba. Anda boleh memuat turun imej ini dan contoh buku nota yang sepadan daripada halaman GitHub tutorial.
Pengesanan Tepi Canny kepada Segmentasi Kontur
Pengesanan Tepi Canny ialah kaedah yang mudah dan berkesan untuk mengenal pasti tepi dalam imej. Ia berfungsi dengan mengesan kawasan perubahan intensiti pantas, yang selalunya sempadan objek. Teknik ini menghasilkan garis besar "tepi nipis" dengan menggunakan ambang keamatan. Mari kita selami pelaksanaannya menggunakan OpenCV.
Contoh: Mengesan Tepi dalam Imej Satelit
Di sini, kami menggunakan imej satelit Osaka, khususnya kuburan kofun, sebagai kes ujian.
import cv2
import numpy as np
import matplotlib.pyplot as plt
files = sorted(glob("SAT*.png")) #Get png files
print(len(files))
img=cv2.imread(files[0])
use_image= img[0:600,700:1300]
gray = cv2.cvtColor(use_image, cv2.COLOR_BGR2GRAY)
#Stadard values
min_val = 100
max_val = 200
# Apply Canny Edge Detection
edges = cv2.Canny(gray, min_val, max_val)
#edges = cv2.Canny(gray, min_val, max_val,apertureSize=5,L2gradient = True )
False
# Show the result
plt.figure(figsize=(15, 5))
plt.subplot(131), plt.imshow(cv2.cvtColor(use_image, cv2.COLOR_BGR2RGB))
plt.title('Original Image'), plt.axis('off')
plt.subplot(132), plt.imshow(gray, cmap='gray')
plt.title('Grayscale Image'), plt.axis('off')
plt.subplot(133), plt.imshow(edges, cmap='gray')
plt.title('Canny Edges'), plt.axis('off')
plt.show()

Pinggir keluaran menggariskan dengan jelas bahagian busut kubur kofun dan kawasan lain yang menarik. Walau bagaimanapun, beberapa kawasan terlepas kerana ambang yang tajam. Hasilnya sangat bergantung pada pilihan min_val dan max_val, serta kualiti imej.
Untuk mempertingkatkan pengesanan tepi, kami boleh mempraproses imej untuk menyebarkan keamatan piksel dan mengurangkan hingar. Ini boleh dicapai menggunakan penyamaan histogram (cv2.equalizeHist()) dan kekaburan Gaussian (cv2.GaussianBlur()).
use_image= img[0:600,700:1300]
gray = cv2.cvtColor(use_image, cv2.COLOR_BGR2GRAY)
gray_og = gray.copy()
gray = cv2.equalizeHist(gray)
gray = cv2.GaussianBlur(gray, (9, 9),1)
plt.figure(figsize=(15, 5))
plt.subplot(121), plt.imshow(gray, cmap='gray')
plt.title('Grayscale Image')
plt.subplot(122)
_= plt.hist(gray.ravel(), 256, [0,256],label="Equalized")
_ = plt.hist(gray_og.ravel(), 256, [0,256],label="Original",histtype='step')
plt.legend()
plt.title('Grayscale Histogram')
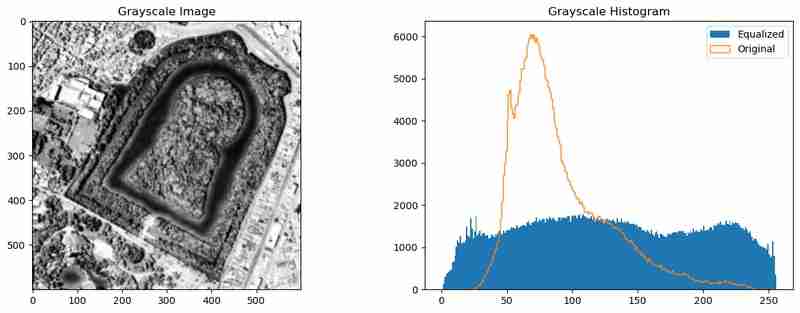
Prapemprosesan ini meratakan taburan keamatan dan melicinkan imej, yang membantu algoritma Pengesanan Tepi Canny menangkap tepi yang lebih bermakna.
Tepi berguna, tetapi ia hanya menunjukkan sempadan. Untuk membahagikan kawasan tertutup, kami menukar tepi kepada kontur dan menggambarkannya.
# Edges to contours
contours, hierarchy = cv2.findContours(edges, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# Calculate contour areas
areas = [cv2.contourArea(contour) for contour in contours]
# Normalize areas for the colormap
normalized_areas = np.array(areas)
if normalized_areas.max() > 0:
normalized_areas = normalized_areas / normalized_areas.max()
# Create a colormap
cmap = plt.cm.jet
# Plot the contours with the color map
plt.figure(figsize=(10, 10))
plt.subplot(1,2,1)
plt.imshow(gray, cmap='gray', alpha=0.5) # Display the grayscale image in the background
mask = np.zeros_like(use_image)
for contour, norm_area in zip(contours, normalized_areas):
color = cmap(norm_area) # Map the normalized area to a color
color = [int(c*255) for c in color[:3]]
cv2.drawContours(mask, [contour], -1, color,-1 ) # Draw contours on the image
plt.subplot(1,2,2)
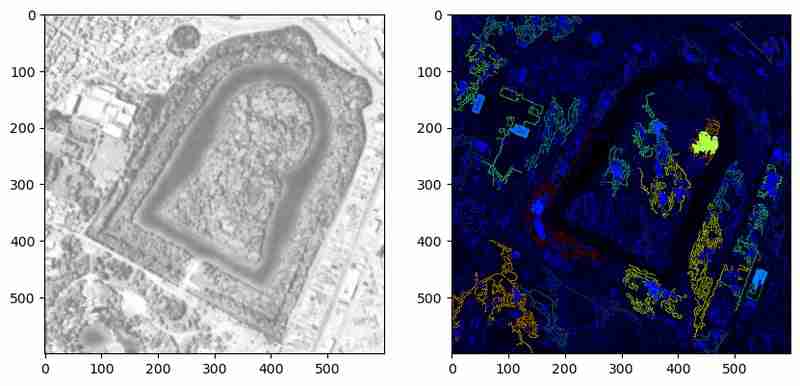
Kaedah di atas menyerlahkan kontur yang dikesan dengan warna yang mewakili kawasan relatifnya. Visualisasi ini membantu mengesahkan sama ada kontur membentuk badan tertutup atau hanya garisan. Walau bagaimanapun, dalam contoh ini, banyak kontur kekal sebagai poligon tidak tertutup. Prapemprosesan lanjut atau penalaan parameter boleh menangani had ini.
Dengan menggabungkan analisis prapemprosesan dan kontur, Pengesanan Tepi Canny menjadi alat yang berkuasa untuk mengenal pasti sempadan objek dalam imej. Walau bagaimanapun, ia berfungsi paling baik apabila objek ditakrifkan dengan baik dan hingar adalah minimum. Seterusnya, kami akan meneroka K-Means Clustering untuk membahagikan imej mengikut warna, menawarkan perspektif berbeza pada data yang sama.
KMean Pengelompokan
K-Means Clustering ialah kaedah popular dalam sains data untuk mengumpulkan item yang serupa ke dalam kelompok, dan ia amat berkesan untuk membahagikan imej berdasarkan persamaan warna. Fungsi cv2.kmeans OpenCV memudahkan proses ini, menjadikannya boleh diakses untuk tugas seperti pembahagian objek, penyingkiran latar belakang atau analisis visual.
Dalam bahagian ini, kami akan menggunakan K-Means Clustering untuk membahagikan imej busut pengebumian kofun kepada kawasan dengan warna yang serupa.
Untuk bermula, kami menggunakan K-Means Clustering pada nilai RGB imej, menganggap setiap piksel sebagai titik data.
import cv2
import numpy as np
import matplotlib.pyplot as plt
files = sorted(glob("SAT*.png")) #Get png files
print(len(files))
img=cv2.imread(files[0])
use_image= img[0:600,700:1300]
gray = cv2.cvtColor(use_image, cv2.COLOR_BGR2GRAY)
#Stadard values
min_val = 100
max_val = 200
# Apply Canny Edge Detection
edges = cv2.Canny(gray, min_val, max_val)
#edges = cv2.Canny(gray, min_val, max_val,apertureSize=5,L2gradient = True )
False
# Show the result
plt.figure(figsize=(15, 5))
plt.subplot(131), plt.imshow(cv2.cvtColor(use_image, cv2.COLOR_BGR2RGB))
plt.title('Original Image'), plt.axis('off')
plt.subplot(132), plt.imshow(gray, cmap='gray')
plt.title('Grayscale Image'), plt.axis('off')
plt.subplot(133), plt.imshow(edges, cmap='gray')
plt.title('Canny Edges'), plt.axis('off')
plt.show()

Dalam imej bersegmen, bukit kubur dan kawasan sekitarnya dikelompokkan menjadi warna yang berbeza. Walau bagaimanapun, bunyi bising dan variasi kecil dalam warna membawa kepada kelompok berpecah-belah, yang boleh menjadikan tafsiran mencabar.
Untuk mengurangkan hingar dan mencipta gugusan yang lebih lancar, kami boleh menggunakan kabur median sebelum menjalankan K-Means.
use_image= img[0:600,700:1300]
gray = cv2.cvtColor(use_image, cv2.COLOR_BGR2GRAY)
gray_og = gray.copy()
gray = cv2.equalizeHist(gray)
gray = cv2.GaussianBlur(gray, (9, 9),1)
plt.figure(figsize=(15, 5))
plt.subplot(121), plt.imshow(gray, cmap='gray')
plt.title('Grayscale Image')
plt.subplot(122)
_= plt.hist(gray.ravel(), 256, [0,256],label="Equalized")
_ = plt.hist(gray_og.ravel(), 256, [0,256],label="Original",histtype='step')
plt.legend()
plt.title('Grayscale Histogram')

Imej kabur menghasilkan gugusan yang lebih licin, mengurangkan hingar dan menjadikan kawasan yang tersegmentasi lebih padu secara visual.
Untuk lebih memahami hasil pembahagian, kami boleh mencipta peta warna bagi warna kluster yang unik, menggunakan matplotlib plt.fill_between;
# Edges to contours
contours, hierarchy = cv2.findContours(edges, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# Calculate contour areas
areas = [cv2.contourArea(contour) for contour in contours]
# Normalize areas for the colormap
normalized_areas = np.array(areas)
if normalized_areas.max() > 0:
normalized_areas = normalized_areas / normalized_areas.max()
# Create a colormap
cmap = plt.cm.jet
# Plot the contours with the color map
plt.figure(figsize=(10, 10))
plt.subplot(1,2,1)
plt.imshow(gray, cmap='gray', alpha=0.5) # Display the grayscale image in the background
mask = np.zeros_like(use_image)
for contour, norm_area in zip(contours, normalized_areas):
color = cmap(norm_area) # Map the normalized area to a color
color = [int(c*255) for c in color[:3]]
cv2.drawContours(mask, [contour], -1, color,-1 ) # Draw contours on the image
plt.subplot(1,2,2)

Penggambaran ini memberikan cerapan tentang warna dominan dalam imej dan nilai RGB yang sepadan, yang boleh berguna untuk analisis selanjutnya. AS kita boleh menutup dan memilih kawasan kod warna saya sekarang.
Bilangan kluster (K) memberi kesan ketara kepada keputusan. Meningkatkan K menghasilkan pembahagian yang lebih terperinci, manakala nilai yang lebih rendah menghasilkan pengelompokan yang lebih luas. Untuk mencuba, kita boleh mengulangi berbilang nilai K.
import cv2
import numpy as np
import matplotlib.pyplot as plt
files = sorted(glob("SAT*.png")) #Get png files
print(len(files))
img=cv2.imread(files[0])
use_image= img[0:600,700:1300]
gray = cv2.cvtColor(use_image, cv2.COLOR_BGR2GRAY)
#Stadard values
min_val = 100
max_val = 200
# Apply Canny Edge Detection
edges = cv2.Canny(gray, min_val, max_val)
#edges = cv2.Canny(gray, min_val, max_val,apertureSize=5,L2gradient = True )
False
# Show the result
plt.figure(figsize=(15, 5))
plt.subplot(131), plt.imshow(cv2.cvtColor(use_image, cv2.COLOR_BGR2RGB))
plt.title('Original Image'), plt.axis('off')
plt.subplot(132), plt.imshow(gray, cmap='gray')
plt.title('Grayscale Image'), plt.axis('off')
plt.subplot(133), plt.imshow(edges, cmap='gray')
plt.title('Canny Edges'), plt.axis('off')
plt.show()

Hasil pengelompokan untuk nilai K yang berbeza mendedahkan pertukaran antara perincian dan kesederhanaan:
?Nilai K yang lebih rendah (mis., 2-3): Kelompok luas dengan perbezaan yang jelas, sesuai untuk pembahagian peringkat tinggi.
?Nilai K yang lebih tinggi (cth., 12-15): Pembahagian yang lebih terperinci, tetapi pada kos peningkatan kerumitan dan potensi pembahagian berlebihan.
K-Means Clustering ialah teknik yang berkuasa untuk membahagikan imej berdasarkan persamaan warna. Dengan langkah prapemprosesan yang betul, ia menghasilkan kawasan yang jelas dan bermakna. Walau bagaimanapun, prestasinya bergantung pada pilihan K, kualiti imej input, dan prapemprosesan yang digunakan. Seterusnya, kami akan meneroka Algoritma Tadahan Air, yang menggunakan ciri topografi untuk mencapai pembahagian objek dan kawasan yang tepat.
Segmentasi Tadahan Air
Algoritma Tadahan Air diilhamkan oleh peta topografi, di mana tadahan air membahagikan lembangan saliran. Kaedah ini menganggap nilai keamatan skala kelabu sebagai ketinggian, dengan berkesan mewujudkan "puncak" dan "lembah." Dengan mengenal pasti kawasan yang menarik, algoritma boleh membahagikan objek dengan sempadan yang tepat. Ia amat berguna untuk mengasingkan objek yang bertindih, menjadikannya pilihan yang bagus untuk senario kompleks seperti pembahagian sel, pengesanan objek dan membezakan ciri yang padat.
Langkah pertama ialah pramemproses imej untuk meningkatkan ciri, diikuti dengan menggunakan Algoritma Tadahan Air.
use_image= img[0:600,700:1300]
gray = cv2.cvtColor(use_image, cv2.COLOR_BGR2GRAY)
gray_og = gray.copy()
gray = cv2.equalizeHist(gray)
gray = cv2.GaussianBlur(gray, (9, 9),1)
plt.figure(figsize=(15, 5))
plt.subplot(121), plt.imshow(gray, cmap='gray')
plt.title('Grayscale Image')
plt.subplot(122)
_= plt.hist(gray.ravel(), 256, [0,256],label="Equalized")
_ = plt.hist(gray_og.ravel(), 256, [0,256],label="Original",histtype='step')
plt.legend()
plt.title('Grayscale Histogram')
Wilayah dan sempadan yang tersegmentasi boleh divisualisasikan bersama langkah pemprosesan perantaraan.

# Edges to contours
contours, hierarchy = cv2.findContours(edges, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# Calculate contour areas
areas = [cv2.contourArea(contour) for contour in contours]
# Normalize areas for the colormap
normalized_areas = np.array(areas)
if normalized_areas.max() > 0:
normalized_areas = normalized_areas / normalized_areas.max()
# Create a colormap
cmap = plt.cm.jet
# Plot the contours with the color map
plt.figure(figsize=(10, 10))
plt.subplot(1,2,1)
plt.imshow(gray, cmap='gray', alpha=0.5) # Display the grayscale image in the background
mask = np.zeros_like(use_image)
for contour, norm_area in zip(contours, normalized_areas):
color = cmap(norm_area) # Map the normalized area to a color
color = [int(c*255) for c in color[:3]]
cv2.drawContours(mask, [contour], -1, color,-1 ) # Draw contours on the image
plt.subplot(1,2,2)
Algoritma berjaya mengenal pasti kawasan yang berbeza dan melukis sempadan yang jelas di sekeliling objek. Dalam contoh ini, busut kubur kofun dibahagikan dengan tepat. Walau bagaimanapun, prestasi algoritma sangat bergantung pada langkah prapemprosesan seperti ambang, penyingkiran hingar dan operasi morfologi.
Menambah prapemprosesan lanjutan, seperti penyamaan histogram atau pengaburan adaptif, boleh meningkatkan lagi hasil. Contohnya:
# Kmean color segmentation
use_image= img[0:600,700:1300]
#use_image = cv2.medianBlur(use_image, 15)
# Reshape image for k-means
pixel_values = use_image.reshape((-1, 3)) if len(use_image.shape) == 3 else use_image.reshape((-1, 1))
pixel_values = np.float32(pixel_values)
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
K = 3
attempts=10
ret,label,center=cv2.kmeans(pixel_values,K,None,criteria,attempts,cv2.KMEANS_PP_CENTERS)
centers = np.uint8(center)
segmented_data = centers[label.flatten()]
segmented_image = segmented_data.reshape(use_image.shape)
plt.figure(figsize=(10, 6))
plt.subplot(1,2,1),plt.imshow(use_image[:,:,::-1])
plt.title("RGB View")
plt.subplot(1,2,2),plt.imshow(segmented_image[:,:,[2,1,0]])
plt.title(f"Kmean Segmented Image K={K}")

Dengan pelarasan ini, lebih banyak kawasan boleh dibahagikan dengan tepat dan artifak bunyi boleh diminimumkan.
Algoritma Watershed cemerlang dalam senario yang memerlukan persempadanan yang tepat dan pengasingan objek bertindih. Dengan memanfaatkan teknik prapemprosesan, ia boleh mengendalikan imej yang kompleks seperti kawasan kuburan kofun dengan berkesan. Walau bagaimanapun, kejayaannya bergantung pada penalaan parameter dan prapemprosesan yang teliti.
Kesimpulan
Segmentasi ialah alat penting dalam analisis imej, menyediakan laluan untuk mengasingkan dan memahami elemen yang berbeza dalam imej. Tutorial ini menunjukkan tiga teknik pembahagian yang berkuasa—Canny Edge Detection, K-Means Clustering, dan Watershed Algorithm—setiap satu disesuaikan untuk aplikasi tertentu. Daripada menggariskan busut perkuburan kofun purba di Osaka kepada pengelompokan landskap bandar dan mengasingkan kawasan yang berbeza, kaedah ini menyerlahkan kepelbagaian OpenCV dalam menangani cabaran dunia sebenar.
Sekarang pergi dan gunakan beberapa kaedah di sana pada aplikasi pilihan anda dan ulas serta kongsikan hasilnya. Juga jika anda tahu kaedah segmentasi mudah lain sila kongsi juga
Atas ialah kandungan terperinci [Python-CVImage Segmentation : Canny Edges, Watershed dan Kaedah K-Means. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undress AI Tool
Gambar buka pakaian secara percuma

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Polimorfisme dalam kelas python
Jul 05, 2025 am 02:58 AM
Polimorfisme dalam kelas python
Jul 05, 2025 am 02:58 AM
Polimorfisme adalah konsep teras dalam pengaturcaraan berorientasikan objek Python, merujuk kepada "satu antara muka, pelbagai pelaksanaan", yang membolehkan pemprosesan bersatu pelbagai jenis objek. 1. Polimorfisme dilaksanakan melalui penulisan semula kaedah. Subkelas boleh mentakrifkan semula kaedah kelas induk. Sebagai contoh, kaedah bercakap () kelas haiwan mempunyai pelaksanaan yang berbeza dalam subkelas anjing dan kucing. 2. Penggunaan praktikal polimorfisme termasuk memudahkan struktur kod dan meningkatkan skalabilitas, seperti memanggil kaedah cabutan () secara seragam dalam program lukisan grafik, atau mengendalikan tingkah laku umum watak -watak yang berbeza dalam pembangunan permainan. 3. Polimorfisme pelaksanaan Python perlu memenuhi: Kelas induk mentakrifkan kaedah, dan kelas kanak -kanak mengatasi kaedah, tetapi tidak memerlukan warisan kelas induk yang sama. Selagi objek melaksanakan kaedah yang sama, ini dipanggil "jenis itik". 4. Perkara yang perlu diperhatikan termasuk penyelenggaraan
 Bagaimana saya menulis 'Hello, World!' Yang mudah! program dalam python?
Jun 24, 2025 am 12:45 AM
Bagaimana saya menulis 'Hello, World!' Yang mudah! program dalam python?
Jun 24, 2025 am 12:45 AM
"Hello, dunia!" Program adalah contoh paling asas yang ditulis dalam Python, yang digunakan untuk menunjukkan sintaks asas dan mengesahkan bahawa persekitaran pembangunan dikonfigurasi dengan betul. 1. Ia dilaksanakan melalui garis cetakan kod ("Hello, World!"), Dan selepas berlari, teks yang ditentukan akan dikeluarkan pada konsol; 2. Langkah -langkah berjalan termasuk memasang python, menulis kod dengan editor teks, menyimpan sebagai fail .py, dan melaksanakan fail di terminal; 3. Kesilapan umum termasuk kurungan atau petikan yang hilang, penyalahgunaan cetakan modal, tidak menyimpan format .py, dan kesilapan persekitaran yang menjalankan; 4. Alat pilihan termasuk terminal editor teks tempatan, editor dalam talian (seperti replit.com)
 Apakah algoritma dalam Python, dan mengapa mereka penting?
Jun 24, 2025 am 12:43 AM
Apakah algoritma dalam Python, dan mengapa mereka penting?
Jun 24, 2025 am 12:43 AM
Algorithmmsinpythonareessentialforefficientplemlemen-solvinginprogramming.theyarestep-by-stepproceduresedtosolvetaskslikesorting, carian, anddatamanipulation.CommontypesincludesortalgorithmslinybineShmseCkeCkeCkeCkeCkeCkeCkeCkeCkeCkeCkeCkeCkeCkeCkeChmmsline, carianShmseKorithmseCkeCkeChmmmslareLineShmseKorithmmslareLineShmmslikeCkeCkeCksort,
 Apakah senarai pengirim di Python?
Jun 29, 2025 am 02:15 AM
Apakah senarai pengirim di Python?
Jun 29, 2025 am 02:15 AM
Listslicinginpythonextractsaportionofalistusingindices.1.itusesthesyntaxlist [start: end: step], wherestartislusive, endisexclusive, andstepdefinestheinterval.2.ifstartorendareomitt
 Python `@Classmethod` Decorator dijelaskan
Jul 04, 2025 am 03:26 AM
Python `@Classmethod` Decorator dijelaskan
Jul 04, 2025 am 03:26 AM
Kaedah kelas adalah kaedah yang ditakrifkan dalam python melalui penghias @classmethod. Parameter pertamanya adalah kelas itu sendiri (CLS), yang digunakan untuk mengakses atau mengubah keadaan kelas. Ia boleh dipanggil melalui kelas atau contoh, yang mempengaruhi seluruh kelas dan bukannya contoh tertentu; Sebagai contoh, dalam kelas orang, kaedah show_count () mengira bilangan objek yang dibuat; Apabila menentukan kaedah kelas, anda perlu menggunakan penghias @classmethod dan namakan parameter pertama CLS, seperti kaedah change_var (new_value) untuk mengubah suai pembolehubah kelas; Kaedah kelas adalah berbeza daripada kaedah contoh (parameter diri) dan kaedah statik (tiada parameter automatik), dan sesuai untuk kaedah kilang, pembina alternatif, dan pengurusan pembolehubah kelas. Kegunaan biasa termasuk:
 Argumen dan Parameter Fungsi Python
Jul 04, 2025 am 03:26 AM
Argumen dan Parameter Fungsi Python
Jul 04, 2025 am 03:26 AM
Parameter adalah ruang letak apabila menentukan fungsi, sementara argumen adalah nilai khusus yang diluluskan ketika memanggil. 1. Parameter kedudukan perlu diluluskan, dan perintah yang salah akan membawa kepada kesilapan dalam hasilnya; 2. Parameter kata kunci ditentukan oleh nama parameter, yang boleh mengubah pesanan dan meningkatkan kebolehbacaan; 3. Nilai parameter lalai diberikan apabila ditakrifkan untuk mengelakkan kod pendua, tetapi objek berubah harus dielakkan sebagai nilai lalai; 4 Args dan *kwargs boleh mengendalikan bilangan parameter yang tidak pasti dan sesuai untuk antara muka umum atau penghias, tetapi harus digunakan dengan berhati -hati untuk mengekalkan kebolehbacaan.
 Bagaimana saya menggunakan modul CSV untuk bekerja dengan fail CSV di Python?
Jun 25, 2025 am 01:03 AM
Bagaimana saya menggunakan modul CSV untuk bekerja dengan fail CSV di Python?
Jun 25, 2025 am 01:03 AM
Modul CSV Python menyediakan cara mudah untuk membaca dan menulis fail CSV. 1. Apabila membaca fail CSV, anda boleh menggunakan csv.reader () untuk membaca garis mengikut baris dan mengembalikan setiap baris data sebagai senarai rentetan; Jika anda perlu mengakses data melalui nama lajur, anda boleh menggunakan csv.dictreader () untuk memetakan setiap baris ke dalam kamus. 2. Apabila menulis ke fail CSV, gunakan kaedah CSV.Writer () dan hubungi Writerow () atau Writerows () untuk menulis satu baris data tunggal atau berbilang; Jika anda ingin menulis data kamus, gunakan csv.dictwriter (), anda perlu menentukan nama lajur terlebih dahulu dan tulis tajuk melalui WriteHeader (). 3. Semasa mengendalikan kes kelebihan, modul secara automatik mengendalikannya
 Terangkan penjana python dan iterators.
Jul 05, 2025 am 02:55 AM
Terangkan penjana python dan iterators.
Jul 05, 2025 am 02:55 AM
Iterator adalah objek yang melaksanakan kaedah __iter __ () dan __Next __ (). Penjana adalah versi Iterator yang dipermudahkan, yang secara automatik melaksanakan kaedah ini melalui kata kunci hasil. 1. Iterator mengembalikan elemen setiap kali dia memanggil seterusnya () dan melemparkan pengecualian berhenti apabila tidak ada lagi elemen. 2. Penjana menggunakan definisi fungsi untuk menghasilkan data atas permintaan, menjimatkan memori dan menyokong urutan tak terhingga. 3. Menggunakan Iterator apabila memproses set sedia ada, gunakan penjana apabila menghasilkan data besar secara dinamik atau penilaian malas, seperti garis pemuatan mengikut baris apabila membaca fail besar. NOTA: Objek yang boleh diperolehi seperti senarai bukanlah pengaliran. Mereka perlu dicipta semula selepas pemalar itu sampai ke penghujungnya, dan penjana hanya boleh melintasi sekali.
