

Tukar dokumen teks ke matriks TF-IDF dengan TFIDFVectorizer
Apr 18, 2025 am 10:26 AM
Artikel ini menerangkan teknik frekuensi frekuensi-inverse frekuensi (TF-IDF), alat penting dalam pemprosesan bahasa semulajadi (NLP) untuk menganalisis data teks. TF-IDF melampaui batasan pendekatan asas beg-kata-kata dengan istilah berat berdasarkan kekerapannya dalam dokumen dan jarang mereka merentasi koleksi dokumen. Ini peningkatan berat badan meningkatkan klasifikasi teks dan meningkatkan keupayaan analisis model pembelajaran mesin. Kami akan menunjukkan cara membina model TF-IDF dari awal dalam Python dan melakukan pengiraan berangka.
Jadual Kandungan
- Syarat Utama dalam TF-IDF
- Kekerapan jangka panjang (TF) dijelaskan
- Frekuensi Dokumen (DF) dijelaskan
- Frekuensi Dokumen Songsang (IDF) dijelaskan
- Memahami TF-IDF
- Pengiraan TF-IDF berangka
- Langkah 1: Mengira kekerapan jangka panjang (TF)
- Langkah 2: Mengira Frekuensi Dokumen Songsang (IDF)
- Langkah 3: Mengira TF-IDF
- Pelaksanaan Python menggunakan dataset terbina dalam
- Langkah 1: Memasang perpustakaan yang diperlukan
- Langkah 2: Mengimport perpustakaan
- Langkah 3: Memuatkan dataset
- Langkah 4: Memulakan
TfidfVectorizer - Langkah 5: Memasang dan mengubah dokumen
- Langkah 6: Memeriksa Matriks TF-IDF
- Kesimpulan
- Soalan yang sering ditanya
Syarat Utama dalam TF-IDF
Sebelum meneruskan, mari kita tentukan istilah utama:
- t : istilah (perkataan individu)
- D : Dokumen (satu set perkataan)
- N : Jumlah dokumen di korpus
- Corpus : Koleksi keseluruhan dokumen
Kekerapan jangka panjang (TF) dijelaskan
Kekerapan jangka panjang (TF) mengukur seberapa kerap istilah muncul dalam dokumen tertentu. TF yang lebih tinggi menunjukkan kepentingan yang lebih besar dalam dokumen itu. Formula adalah:
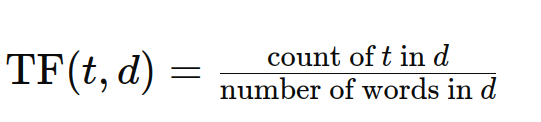
Frekuensi Dokumen (DF) dijelaskan
Kekerapan dokumen (df) mengukur bilangan dokumen dalam korpus yang mengandungi istilah tertentu. Tidak seperti TF, ia mengira kehadiran istilah, bukan kejadiannya. Formula adalah:
Df (t) = bilangan dokumen yang mengandungi istilah t
Frekuensi Dokumen Songsang (IDF) dijelaskan
Kekerapan dokumen songsang (IDF) menilai maklumat mengenai perkataan. Walaupun TF merawat semua istilah sama, kata -kata bawah tanah IDF (seperti kata -kata berhenti) dan istilah yang lebih jarang. Formula adalah:
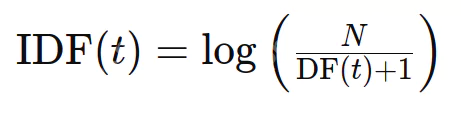
di mana n ialah jumlah dokumen dan df (t) adalah bilangan dokumen yang mengandungi istilah t.
Memahami TF-IDF
TF-IDF menggabungkan kekerapan jangka panjang dan kekerapan dokumen songsang untuk menentukan kepentingan istilah dalam dokumen berbanding dengan keseluruhan korpus. Formula adalah:
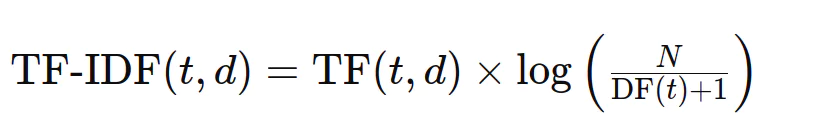
Pengiraan TF-IDF berangka
Mari kita gambarkan pengiraan TF-IDF berangka dengan dokumen contoh:
Dokumen:
- "Langit berwarna biru."
- "Matahari cerah hari ini."
- "Matahari di langit cerah."
- "Kita dapat melihat matahari bersinar, matahari yang cerah."
Berikutan langkah-langkah yang digariskan dalam teks asal, kami mengira TF, IDF, dan kemudian TF-IDF untuk setiap istilah dalam setiap dokumen. (Pengiraan terperinci ditinggalkan di sini untuk keringkasan, tetapi mereka mencerminkan contoh asal.)
Pelaksanaan Python menggunakan dataset terbina dalam
Bahagian ini menunjukkan pengiraan TF-IDF menggunakan TfidfVectorizer Scikit-Learn dan dataset 20 kumpulan berita.
Langkah 1: Memasang perpustakaan yang diperlukan
PIP Pasang SCIKIT-Learn
Langkah 2: Mengimport perpustakaan
Import Pandas sebagai PD dari sklearn.datasets import fetch_20newsgroups dari sklearn.feature_extraction.text import tfidfvectorizer
Langkah 3: Memuatkan dataset
kumpulan berita = fetch_20NewSgroups (subset = 'kereta api')
Langkah 4: Memulakan TfidfVectorizer
vectorizer = tfidfvectorizer (stop_words = 'english', max_features = 1000)
Langkah 5: Memasang dan mengubah dokumen
tfidf_matrix = vectorizer.fit_transform (newsgroups.data)
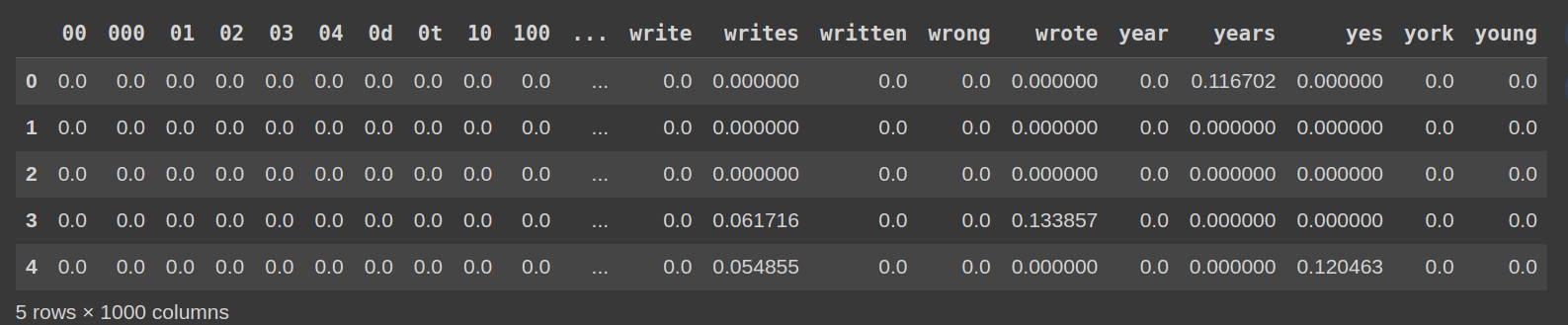
Langkah 6: Memeriksa Matriks TF-IDF
df_tfidf = pd.dataFrame (tfidf_matrix.toarray (), lajur = vectorizer.get_feature_names_out ()) df_tfidf.head ()
Kesimpulan
Menggunakan 20 kumpulan kumpulan berita dan TfidfVectorizer , kami dengan cekap mengubah dokumen teks ke dalam matriks TF-IDF. Matriks ini mewakili kepentingan setiap istilah, membolehkan pelbagai tugas NLP seperti klasifikasi teks dan kluster. TfidfVectorizer Scikit-Learn memudahkan proses ini dengan ketara.
Soalan yang sering ditanya
Seksyen Soalan Lazim tetap tidak berubah, menangani sifat logaritma IDF, skalabilitas kepada dataset yang besar, batasan TF-IDF (mengabaikan perintah dan konteks perkataan), dan aplikasi umum (enjin carian, klasifikasi teks, kluster, ringkasan).
Atas ialah kandungan terperinci Tukar dokumen teks ke matriks TF-IDF dengan TFIDFVectorizer. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undress AI Tool
Gambar buka pakaian secara percuma

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Alternatif Notebooklm Top 7 Top
Jun 17, 2025 pm 04:32 PM
Alternatif Notebooklm Top 7 Top
Jun 17, 2025 pm 04:32 PM
NotebookLM Google adalah alat pengambilan nota AI pintar yang dikuasakan oleh Gemini 2.5, yang cemerlang dalam meringkaskan dokumen. Walau bagaimanapun, ia masih mempunyai batasan penggunaan alat, seperti topi sumber, pergantungan awan, dan ciri "Discover" baru -baru ini
 Dari Adopsi ke Kelebihan: 10 Trend Membentuk LLMS Enterprise pada tahun 2025
Jun 20, 2025 am 11:13 AM
Dari Adopsi ke Kelebihan: 10 Trend Membentuk LLMS Enterprise pada tahun 2025
Jun 20, 2025 am 11:13 AM
Berikut adalah sepuluh trend yang menarik yang membentuk semula landskap AI perusahaan. Komitmen kewangan untuk llmsorganizations secara signifikan meningkatkan pelaburan mereka di LLM, dengan 72% menjangkakan perbelanjaan mereka meningkat tahun ini. Pada masa ini, hampir 40% a
 Pelabur AI terjebak dengan terhenti? 3 Laluan Strategik untuk Membeli, Membina, atau Berkongsi dengan Vendor AI
Jul 02, 2025 am 11:13 AM
Pelabur AI terjebak dengan terhenti? 3 Laluan Strategik untuk Membeli, Membina, atau Berkongsi dengan Vendor AI
Jul 02, 2025 am 11:13 AM
Pelaburan adalah berkembang pesat, tetapi modal sahaja tidak mencukupi. Dengan penilaian yang semakin meningkat dan tersendiri pudar, pelabur dalam dana usaha yang berfokus pada AI mesti membuat keputusan utama: Beli, membina, atau rakan kongsi untuk mendapatkan kelebihan? Inilah cara menilai setiap pilihan dan PR
 Pertumbuhan AI generatif yang tidak boleh dihalang (AI Outlook Bahagian 1)
Jun 21, 2025 am 11:11 AM
Pertumbuhan AI generatif yang tidak boleh dihalang (AI Outlook Bahagian 1)
Jun 21, 2025 am 11:11 AM
Pendedahan: Syarikat saya, Tirias Research, telah berunding untuk IBM, NVIDIA, dan syarikat -syarikat lain yang disebutkan dalam artikel ini. Pemandu Growth Surge dalam penggunaan AI generatif lebih dramatik daripada unjuran yang paling optimis dapat diramalkan. Kemudian, a
 Laporan Gallup Baru: Kesediaan Kebudayaan AI Menuntut Mindset Baru
Jun 19, 2025 am 11:16 AM
Laporan Gallup Baru: Kesediaan Kebudayaan AI Menuntut Mindset Baru
Jun 19, 2025 am 11:16 AM
Jurang antara penggunaan yang meluas dan kesediaan emosi mendedahkan sesuatu yang penting tentang bagaimana manusia terlibat dengan pelbagai sahabat digital mereka. Kami memasuki fasa kewujudan bersama di mana algoritma menenun ke dalam harian kami
 Permulaan ini membantu perniagaan muncul dalam ringkasan carian AI
Jun 20, 2025 am 11:16 AM
Permulaan ini membantu perniagaan muncul dalam ringkasan carian AI
Jun 20, 2025 am 11:16 AM
Hari -hari itu bernombor, terima kasih kepada AI. Cari lalu lintas untuk perniagaan seperti tapak perjalanan kayak dan syarikat edtech Chegg menurun, sebahagiannya kerana 60% carian di laman web seperti Google tidak mengakibatkan pengguna mengklik sebarang pautan, menurut satu stud
 AGI dan AI Superintelligence akan dengan ketara memukul penghalang asumsi siling manusia
Jul 04, 2025 am 11:10 AM
AGI dan AI Superintelligence akan dengan ketara memukul penghalang asumsi siling manusia
Jul 04, 2025 am 11:10 AM
Mari kita bercakap mengenainya. Analisis terobosan AI yang inovatif ini adalah sebahagian daripada liputan lajur Forbes yang berterusan pada AI terkini, termasuk mengenal pasti dan menerangkan pelbagai kerumitan AI yang memberi kesan (lihat pautan di sini). Menuju ke Agi dan
 Cisco mencatatkan perjalanan AI yang agentik di Cisco Live A.S. 2025
Jun 19, 2025 am 11:10 AM
Cisco mencatatkan perjalanan AI yang agentik di Cisco Live A.S. 2025
Jun 19, 2025 am 11:10 AM
Mari kita lihat dengan lebih dekat apa yang saya dapati paling penting - dan bagaimana Cisco dapat membina usaha semasa untuk merealisasikan cita -citanya. (Nota: Cisco adalah pelanggan penasihat firma saya, Moor Insights & Strategy.) Berfokus pada AIS dan CU Agentik dan CU
