合計(jì) 10000 件の関連コンテンツが見つかりました

DockerによってKafkaをインストールする方法
記事の紹介:Dockerの手順を使用してKafkaをインストールする:システムにDockerがインストールされていることを確認(rèn)してください。 Docker Hubから公式のKafka畫像を引く:Docker Pull Confluentinc/CP -Kafka Create and Start Kafka Container:Docker Run -D - Name Kafka -P 9092:9092 Conflentinc/Cp -Kafka使用DockerログKafkaを使用して�����、容器ログを確認(rèn)してKafkaを確認(rèn)します�����。ブラウザからKafkaコントロールパネルにアクセス:http:// localh
2025-04-15
コメント 0
1174

Go で Kafka プロデューサーとコンシューマーを構(gòu)築する
記事の紹介:Apache Kafka は����、リアルタイム データ パイプラインとストリーミング アプリケーションの構(gòu)築に使用される強(qiáng)力な分散ストリーミング プラットフォームです。このブログ投稿では�����、Golang を使用して Kafka プロデューサーとコンシューマーをセットアップする方法を説明します。
前提條件
なれ
2025-01-03
コメント 0
999

Kafka Keysの理解:包括的なガイド
記事の紹介:Apache Kafkaは����、実際のデータパイプラインとアプリケーションを構(gòu)築するために広く使用されている強(qiáng)力な分散イベントストリームプラットフォームです。そのコア関數(shù)の1つは�����、メッセージパーティション�、ソート、ルーティングで重要な役割を果たすKafkaメッセージキーです���。この記事では��、Kafkaキーの概念�����、重要性�����、および実際の例について説明します����。
カフカの鍵は何ですか?
Kafkaでは����、各メッセージには2つの主要なコンポーネントが含まれています。
キー:メッセージが送信されるパーティションを決定します����。
値:メッセージの実際のデータは効果的です。
Kafkaプロデューサーはキーを使用してハッシュ値を計(jì)算し����、メッセージの特定のパーティションを決定します。キーが提供されていない場合�����、メッセージはそれぞれに配布されます
2025-01-29
コメント 0
1152

2025年にApache Kafkaとのデータパイプラインの革命
記事の紹介:この記事では�、2025年までにデータパイプラインアーキテクチャにおけるApache Kafkaの役割を検証します。データボリュームの爆発�����、リアルタイム分析の需要��、複雑なデータソースなどの課題に対処します�。 この記事は、Kafkaのスケーラビリティ����、リアルタイムカペブを強(qiáng)調(diào)しています
2025-03-07
コメント 0
508

リアクティブなKafkaストリームとSpring WebFluxを使用します
記事の紹介:この記事では、リアクティブなKafkaストリームとSpring WebFluxを使用して�����、レスポンシブでスケーラブルなイベント駆動(dòng)型アプリの構(gòu)築について説明します��。 Kafka Consumer SettingsとProject Reactor Operatorsを介した効率的なバックプレッシャーの取り扱いを強(qiáng)調(diào)し���、包括的
2025-03-07
コメント 0
956
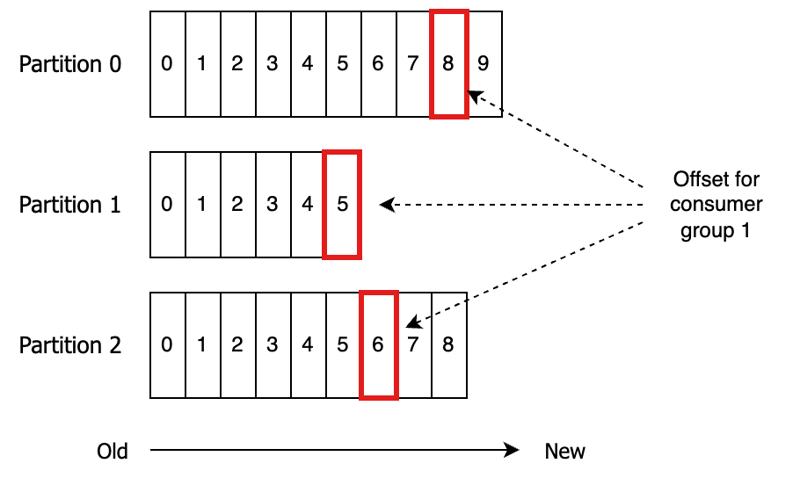
Kafka Consumer - 消費(fèi)者グループのオフセットをコミットします
記事の紹介:Kafka Consumer Groupのオフセットの理解:包括的なガイド
このガイドでは����、メッセージの消費(fèi)の進(jìn)行を追跡するために重要なKafka Consumer Groupのオフセットを探ります���。 各消費(fèi)者グループは���、消費(fèi)する各パーティションのオフセットを維持し���、
2025-01-26
コメント 0
1116

Kafkaメッセージ承認(rèn)オプション
記事の紹介:この記事では、Kafkaのメッセージ承認(rèn)オプションについて説明します:自動(dòng)���、マニュアル同期�、マニュアル非同期���、および特定のオフセットを備えたマニュアル���。 スループットと信頼性の間のパフォーマンスのトレードオフを分析し、SELEの読者を?qū)Г蓼?/p>
2025-03-07
コメント 0
702
Kafka プロトコル実踐ガイド
記事の紹介:私は Apache Kafka プロトコルを低レベルでかなり使用しました。公式ガイドだけに従ってこれを始めるのは簡単ではなかったので���、コードを何度も読みました���。この投稿では、pri から段階的にガイドして有利なスタートを切りたいと思います�。
2024-12-28
コメント 0
588

GenAI の高速化: MySQL から Kafka へのデータのストリーミング
記事の紹介:AI の時(shí)代において、Apache Kafka はリアルタイムのデータ ストリーミングと処理における高いパフォーマンスにより極めて重要な役割を果たしています��。多くの組織は����、効率とビジネスの機(jī)敏性を高めるためにデータを Kafka に統(tǒng)合しようとしています。この場合
2024-11-03
コメント 0
341

RabbitMQ と Kafka: Java アプリケーションに適したメッセージ ブローカーの選択
記事の紹介:RabbitMQ と Kafka の比較:
メッセージ ブローカーのニーズに合わせて RabbitMQ と Kafka のどちらを選択するかを決定する場合は����、それぞれの獨(dú)自の強(qiáng)みと最適な使用例を理解することが重要です。
RabbitMQ は���、プッシュ モデルを使用してデリバリを行う従來のメッセージ ブローカーです�����。
2024-11-12
コメント 0
648

Belay the Metamorphosis: Kafka プロジェクトの分析
記事の紹介:グローバル企業(yè)のプロジェクトのソースコードにどのようなバグが潛んでいるのか考えたことはありますか?オープンソースの Apache Kafka プロジェクトの PVS-Studio 靜的アナライザーによって検出された興味深いバグを見つけるチャンスをお見逃しなく�����。
はじめに
2024-10-16
コメント 0
747
Python を使用した Kafka の初心者ガイド: リアルタイム データ処理とアプリケーション
記事の紹介:カフカの紹介
Kafka は����、Apache によって開発されたオープンソースの分散イベント ストリーミング プラットフォームです。
もともと LinkedIn によって作成されたこのサービスは�、高スループット、フォールトトレラント���、リアルタイムのデータ ストリーミングを処理するように設(shè)計(jì)されています��。
Kafka を使用すると��、システムは次のことを行うことができます��。
2024-11-05
コメント 0
1253

Kafka で配信および注文されたメッセージを取得して消費(fèi)する方法
記事の紹介:Apache Kafka でイベントが完全に一貫した順序で送信および消費(fèi)されるようにするには�����、メッセージの分割とコンシューマの割り當(dāng)てがどのように機(jī)能するかを理解することが不可欠です�。
Kafka でのパーティションの使用
パーティション
2024-11-06
コメント 0
500

GOアプリケーションでKafkaに接続して使用する方法は��?
記事の紹介:Goと接続してKafkaを使用するための重要な手順には�����、Kafka-Goライブラリのインストール、プロデューサーの執(zhí)筆メッセージの送信�����、消費(fèi)者の執(zhí)筆メッセージの受信�、一般的な問題に注意を払うことが含まれます�����。 1. KOMODを介して依存関係を管理するには�、Kafka-goライブラリをインストールします。 2��。プロデューサーを作成して�、ライターを使用して指定されたトピックにメッセージを送信します。 3.消費(fèi)者を作成して�、指定されたトピックからメッセージを引き出すために読者を使用します。 4.ブローカーアドレス���、トピック名����、消費(fèi)者グループの設(shè)定��、パフォーマンスチューニングなどの詳細(xì)に注意してください。
2025-07-17
コメント 0
121

Kafka の基礎(chǔ)と実際の例
記事の紹介:過去數(shù)週間にわたって�����、私は Kafka に飛び込み�、途中でメモを取ってきました。それを整理してブログ投稿として構(gòu)成することにしました��。概念やヒントとは別に�����、NestJS と KafkaJs で構(gòu)築された実踐的な例があります�����。 ��。
2024-12-28
コメント 0
558





